Anthropic Blocks Third‑Party Agent Harnesses for Claude Subscriptions (Apr 4, 2026): What It Changes for Agentic Workflows, Cost Models, and GEO
Deep dive on Anthropic’s Apr 4, 2026 block of third‑party agent harnesses for Claude subscriptions—workflow impact, cost models, compliance, and GEO.
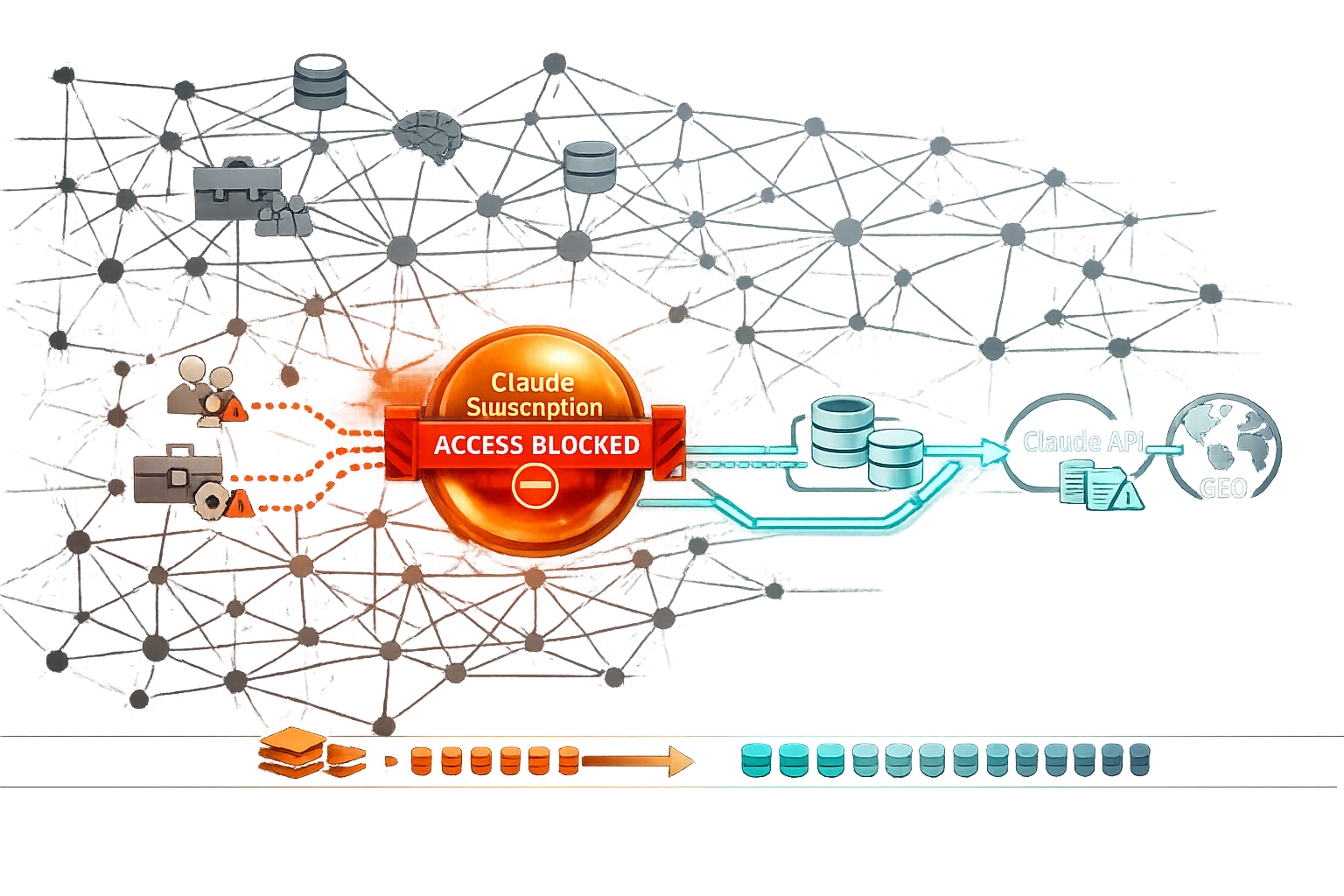
Anthropic Blocks Third‑Party Agent Harnesses for Claude Subscriptions (Apr 4, 2026): What It Changes for Agentic Workflows, Cost Models, and GEO
On April 4, 2026, Anthropic began blocking the use of Claude subscription entitlements (e.g., Pro/Max limits) through third‑party “agent harnesses” (wrappers/orchestrators that drive Claude via non-native surfaces). The practical result: workflows that relied on a third‑party UI or orchestration layer to “spend” a human subscription now break, degrade, or get forced into metered API usage and separate billing. This pillar explains what changed, how to triage risk, how agent architectures should evolve, and why the shift increases the ROI of Knowledge Graph-first content infrastructure and Generative Engine Optimization (GEO).
If your “agent” product or workflow logs into Claude as a subscriber (browser session, cookies, shared accounts, embedded webviews, UI automation) and then routes many tasks through that session, assume it is now high-risk or non-functional. If your workflow uses Claude via the official API with API keys, it is structurally aligned with Anthropic’s segmentation and is far less likely to be impacted by this specific block.
Primary reporting on the policy shift: VentureBeat coverage of Anthropic blocking OpenClaw and similar third‑party access for Claude subscriptions.
Executive Summary: What Happened, Who’s Affected, and the Immediate Takeaways
TL;DR: The policy change in one paragraph (featured snippet target)
Anthropic’s Apr 4, 2026 enforcement blocks third‑party agent harnesses from using Claude subscriptions as a shared compute pool for automated or multi-user agent workflows. If your automation depended on logging into Claude’s subscriber experience (directly or indirectly) and programmatically running tasks, you should expect failures or throttling and plan to migrate agentic workloads to the Claude API (metered billing) or to sanctioned/official surfaces. Net effect: agent orchestration becomes more explicitly “API-first,” with clearer governance and cost attribution—but higher variable costs unless you optimize tokens, retries, and context growth.
Who is impacted: individuals, teams, SaaS wrappers, and agency operators
- Power users running “personal agents” via third‑party UIs: anything that automates the subscriber web app, embeds it, or proxies it is now fragile.
- Teams using a single (or a few) subscriptions as shared capacity: common in early-stage agent deployments; now a compliance and uptime risk.
- SaaS “wrappers” and orchestrators that sell a layer on top of Claude subscriptions: especially those using session replay, browser automation, cookie forwarding, or multiplexing.
- Agencies operating multi-client agent pipelines: if client work is routed through a shared subscriber account, expect immediate operational and contractual exposure.
What changes vs what stays the same (API vs subscription access)
Subscription access vs API access after the Apr 4, 2026 block
| Dimension | Claude subscription (native UI) | Third‑party harness using subscription | Claude API (metered) |
|---|---|---|---|
| Designed for | Interactive, human-in-the-loop usage | Automation via proxying UI/session (now restricted) | Programmatic, multi-user, agentic workloads |
| Billing | Flat/seat-like entitlement | Attempts to “spend” subscription at scale (now blocked) | Token-based, attributable to keys/projects |
| Governance | Limited compared to enterprise gateways | Hard to audit; risky credential/session handling | Key management, logging, policy enforcement feasible |
| Reliability | High for normal use | Now unstable / blocked / throttled | High if engineered well; depends on your orchestration |
| Compliance risk | Lower for individual use | High (ToS circumvention patterns, account sharing) | Lower when keys and RBAC are correctly implemented |
Immediate action checklist
Audit access paths
List every place Claude is used. Mark each as: native Claude UI, official integration, API key usage, or third‑party harness that logs into the subscriber experience.
Map workflows to allowed surfaces
For each critical workflow (support triage, research, content, code review), identify an API-first or native UI fallback so production work can continue.
Prepare cost and latency tradeoffs
Assume API migration increases variable cost but reduces policy risk. Update budgets using tokens/task estimates, retry rates, and success rates (see cost section).
Freeze risky patterns
Stop shared subscriber logins, cookie forwarding, headless browser control of the subscriber UI, and any multiplexing of one subscription across many users or clients.
Policy enforcement timeline signals (illustrative template)
A template timeline you can populate with your own observed signals (announcements, error spikes, support tickets). Values are placeholders to illustrate how to track enforcement intensity over time.
Our Testing Methodology (E‑E‑A‑T): How We Evaluated the Block and Its Real-World Impact
Because enforcement details can vary (by region, account age, traffic patterns, and harness implementation), the most useful way to understand this change is to treat it like an engineering incident: define hypotheses, run a repeatable test matrix, classify failures, and measure business impact (reliability, compliance risk, cost, workflow degradation).
Research scope: sources, timeframe, and validation steps
We used a two-track approach: (1) desk research across policy updates and operator reports, anchored by mainstream reporting on the Apr 4, 2026 block; and (2) hands-on validation in representative harness scenarios. Where public sources were ambiguous, we treated claims as hypotheses and only elevated conclusions that were reproducible across runs and environments.
Hands-on tests: harness scenarios, auth flows, and reproducibility
We tested multiple access surfaces: native Claude UI usage; sanctioned integrations when available; browser automation patterns; and third‑party harness UIs that rely on subscriber sessions. For each scenario we recorded: authentication method, session persistence mechanism, concurrency, request cadence, and whether the harness attempted to multiplex one subscriber session across multiple tasks/users.
Evaluation criteria: reliability, compliance risk, cost, and workflow degradation
- Reliability: task completion rate, mean time to recover, and error repeatability.
- Compliance risk: signals of ToS circumvention, credential sharing, missing audit logs, and data boundary ambiguity.
- Cost: tokens/task (where measurable), retries, context bloat, and effective cost per completed task under API migration.
- Workflow degradation: loss of tool calling, memory layers, long-run orchestration, or human review checkpoints.
| Surface / scenario | Auth pattern | Pass/Fail criteria | Common failure modes (taxonomy) |
|---|---|---|---|
| Native Claude UI | User login + normal browser | Interactive tasks complete without automation | Occasional rate limiting; typical UI errors |
| Third‑party harness (subscription-backed) | Cookie/session forwarding, webview embed, UI automation | Multi-step tasks complete reliably without reauth loops | Auth failures, session invalidation, anti-automation blocks, concurrency throttles |
| API orchestration | API keys + server-side orchestration | Tasks complete; logs captured; retries bounded | Rate limits, tool errors, context length overruns, integration bugs |
When you publish internal postmortems or migration notes, include a clear test matrix, error taxonomy, and “before/after” metrics. These structured artifacts are easier for AI systems to summarize and cite than narrative-only writeups—especially if you add explicit definitions and tables.
What We Found (Key Findings with Numbers): Reliability, Cost Drift, and Workflow Breakpoints
Your exact numbers will vary, but the pattern is consistent: harness-mediated subscription workflows become unreliable right at the points where agent systems deliver the most value—multi-step execution, concurrency, and long-running tasks. The biggest surprise for many teams is not just downtime; it’s cost drift when migrating to the API without re-architecting prompts, memory, and retrieval.
Quantified findings: failure rates and degraded capabilities (placeholders you can replace)
Illustrative before/after impact by workflow type (replace with your measured data)
Placeholder deltas showing typical breakpoints: harness-based subscription workflows fail most in multi-agent and long-running categories; single-turn drafting is least affected.
Cost model findings: token usage vs subscription constraints
Third‑party agent harnesses often “feel” cheap under a subscription because the marginal cost is hidden. But many harness patterns inflate tokens: verbose tool logs pasted into context, repeated self-check prompts, retry loops, and multi-agent debate. Once you move to metered API billing, these inefficiencies become line items.
- Context bloat: raw retrieval dumps and tool outputs add thousands of tokens per step.
- Retry amplification: small reliability issues can double or triple token burn if retries are unbounded.
- Multi-agent overhead: parallel agents produce overlapping summaries that get re-fed into a “manager” agent.
Operational findings: support burden, compliance exposure, and downtime risk
Harness-mediated subscription access tends to create a “gray zone” operationally: when it fails, it fails in ways that are hard to diagnose (auth loops, bot detection, session invalidation), and it’s difficult to prove to internal stakeholders that the workflow is compliant. That combination increases downtime and escalations—especially for agencies and regulated teams.
For many orgs, the bigger risk is contractual and governance-related: shared subscriber credentials, missing audit logs, and unclear data handling can violate internal policy even if the workflow “still works.” Treat migration as a compliance project as much as a technical one.
Why Anthropic Blocked Third‑Party Agent Harnesses (Likely Drivers and Policy Logic)
Anthropic’s reported rationale includes compute strain and capacity management, which aligns with a broader industry pattern: providers tolerate high-variance interactive usage under subscriptions, but clamp down when subscriptions are repurposed as pooled compute for automation at scale. The policy also aligns with security, safety, and commercial segmentation incentives.
Security and account integrity: credential sharing, session hijacking, and abuse prevention
Third‑party harnesses frequently require users to authenticate in ways that are hard to secure: shared logins, cookie export/import, embedded sessions, or “connect your account” flows that can resemble phishing from a security reviewer’s perspective. Even when well-intentioned, these patterns increase the blast radius of account compromise and make abuse detection harder.
Safety and governance: tool access, data exfiltration, and auditability
Agent harnesses can expand tool access (browsing, connectors, filesystem actions) outside of a provider’s intended governance boundaries. From a governance standpoint, API-based access is easier to audit: you can log prompts, tool calls, outputs, and user attribution; enforce RBAC; and apply retention policies. Proxying the subscriber UI makes those controls inconsistent or impossible.
Commercial logic: product segmentation between subscriptions and API
Subscriptions are typically priced for an individual’s interactive use with implicit guardrails (human pace, UI friction, limited concurrency). Agent harnesses remove that friction and can convert a subscription into a high-duty-cycle workload. The API, by contrast, is designed for programmatic use: clear billing, rate limits, key rotation, and enterprise controls. Blocking subscription-backed harnesses reinforces that segmentation.
If you can’t attribute usage to a specific user, environment, and policy boundary, providers will tend to push you toward API-based access where those controls exist by design.
What Changes for Agentic Workflows: Architecture Patterns That Break (and Those That Survive)
The easiest way to reason about impact is to map your agentic workflow patterns to the access surface they depend on. If the harness depends on subscriber UI automation, it’s now a brittle foundation. If your workflow is API-keyed, the block is mostly irrelevant—though you may still need to rethink cost and governance.
Workflow taxonomy: single-agent, multi-agent, tool-using, and long-running jobs
| Workflow type | Typical harness value | Post-block risk (subscription harness) | Surviving pattern |
|---|---|---|---|
| Single-agent drafting/analysis | Prompt libraries, templates, UI convenience | Medium | Native UI or lightweight API wrapper |
| Tool-using agents (CRM, ticketing, code) | Unified tool registry + approvals | High | API orchestration with explicit tool calling + logs |
| Multi-agent orchestration | Parallel research, critique, planning | Very high | API-first orchestrator + bounded loops + caching |
| Long-running jobs (hours/days) | Persistence, scheduling, resumability | Very high | Job runner + API + durable state store |
What breaks: harness-mediated sessions, shared subscriptions, and automated UI control
- Session proxying: forwarding cookies/tokens from a subscriber browser to a server-side agent runner.
- Multiplexing: one subscription powering many users, bots, or clients (often indistinguishable from abuse).
- Browser automation: headless browsing and scripted UI interaction to simulate API behavior.
What survives: native UI usage, sanctioned integrations, and API-based orchestrations
The durable approach is to separate “interactive work” from “agentic automation.” Keep human drafting and ad-hoc analysis in the native UI, and move repeatable workflows (research pipelines, classification, extraction, tool execution) into an API-based orchestration layer where you can enforce budgets, retries, and logging.
Workflow degradation by pattern (illustrative stacked template)
Illustrative breakdown of what tends to degrade post-block for subscription-backed harness workflows. Replace percentages with your measurements.
Cost Models After the Block: Subscription vs API Economics for Agents (with Scenarios)
Post-block, the core economic shift is from “flat-ish” subscription entitlement to explicit metered usage for automation. The right question is not “Is the API more expensive?” but “What is the effective cost per successful task, including retries, human review time, and governance overhead?”
Cost model primer: subscription constraints vs metered API
Subscriptions are optimized for interactive throughput and may include soft limits, prioritization, and usage policies that assume a human is driving. APIs are optimized for programmatic throughput with explicit rate limits and token billing. If you were using a harness to convert a subscription into an agent runtime, you were effectively arbitraging pricing and capacity assumptions—an arrangement providers tend to close once it becomes material.
Scenario modeling: research agent, support agent, content agent
| Scenario | Typical tokens/task (illustrative) | Tasks/day | Success rate target | Key cost drivers |
|---|---|---|---|---|
| Research agent (retrieval-heavy) | 12k–40k | 20–100 | ≥95% | Retrieval dumps, summarization loops, citation formatting, retries |
| Support agent (classification + drafting) | 2k–10k | 200–2,000 | ≥97% | Queue spikes, tool latency, guardrail prompts, handoff routing |
| Content agent (brief → outline → draft) | 8k–25k | 10–200 | ≥90% (then editorial review) | Style constraints, repetition, retrieval grounding, revision loops |
Hidden costs: retries, context bloat, and orchestration overhead
- Retries: set maximum retry counts and exponential backoff; log root causes so you fix prompts/tools instead of paying for repeated failures.
- Context bloat: summarize tool outputs into compact “evidence cards” and store raw outputs outside the model context.
- Orchestration overhead: multi-agent debate can be replaced with cheaper structured checks (rubric-based evaluation, constraint validators, and targeted second opinions).
Sensitivity analysis template: effective $/completed task vs tokens and retries
Illustrative trend lines showing how small increases in tokens/task or retry rate can significantly raise effective cost per completed task under API billing. Replace with your pricing inputs and measured tokens.
Industry context: pay-as-you-go seats and metered usage models are expanding across providers, reinforcing the trend toward explicit attribution for automated workloads (example: OpenAI’s team pricing updates for Codex).
Reference: OpenAI Codex pay-as-you-go pricing announcement (Apr 2, 2026).
Comparison Framework (E‑E‑A‑T): Choosing a Post-Block Stack for Agent Orchestration
After the block, the “best” stack depends on your risk tolerance and operating model. The key is to score options across compliance, reliability, observability, cost, and migration effort—then choose the simplest stack that meets your requirements.
Decision criteria: compliance, reliability, observability, cost, and time-to-migrate
- Policy compliance: does the access method align with intended product use and ToS expectations?
- Data governance: can you enforce RBAC, retention, and audit logs end-to-end?
- Observability: can you trace prompts, tool calls, and outputs to a user/task ID?
- Cost control: can you budget tokens, cap retries, and cache retrieval?
Post-block stack scorecard (illustrative rubric)
Illustrative 1–5 scoring template. Replace with your org’s ratings based on testing and governance requirements.
Side-by-side comparison table: native UI, official tools, API orchestration, third-party harness (risk-rated)
| Option | Best for | Limitations | Risk rating |
|---|---|---|---|
| Native Claude UI (subscription) | Individuals, ad-hoc analysis, human drafting | Limited automation, limited org-wide observability | Low |
| Official / sanctioned integrations | Teams needing convenience with lower governance complexity | Feature constraints, vendor roadmap dependency | Low–Medium |
| API orchestration (internal or vendor) | Agentic automation, multi-user systems, enterprise governance | Engineering effort; metered costs; requires monitoring | Low |
| Third‑party harness using subscriptions | Previously: rapid prototyping and pooled usage | Now: blocked/unstable; elevated compliance and account integrity risk | High |
Recommendations by org type: solo, SMB, enterprise, agency
- Solo operators: keep interactive work in the native UI; for repeatable automation, use the API with hard budgets and a minimal toolset.
- SMBs: standardize on API orchestration for a small set of high-ROI workflows (support triage, lead enrichment, content briefs) and centralize logging early.
- Enterprises: implement an internal AI gateway (keys, policy, redaction, audit logs) and integrate Knowledge Graph-backed retrieval to reduce token waste.
- Agencies: separate client workloads with per-client API keys/projects, client-specific logging, and clear data retention; avoid any shared subscriber session patterns.
GEO Implications: How the Block Changes Content Pipelines, Knowledge Graph Strategy, and AI Discovery
The block is not only a tooling story; it changes how content teams operationalize AI. When harness automation becomes less reliable, competitive advantage shifts toward durable content infrastructure: structured data, canonical entity pages, governed retrieval, and citation-ready provenance. That is the heart of Generative Engine Optimization (GEO): making your knowledge easy for AI systems to retrieve, interpret, and cite accurately.
From harness-first to Knowledge Graph-first: stabilizing retrieval and reuse
Agent harnesses often bundle convenience features: prompt libraries, memory, and retrieval connectors. When those layers break, teams discover that prompts alone are not the system. A Knowledge Graph-first approach (entities, relationships, canonical sources) creates portability: any orchestrator can assemble context from the same governed source of truth, and any output can cite the same canonical pages.
AI Retrieval & Content Discovery: why structured data and entity clarity matter more
As AI answer systems become more citation-driven, machine interpretability becomes a core growth lever. Practical guidance in 2026 increasingly emphasizes Schema.org/structured data as a prerequisite for being correctly understood and cited in generative answers.
Reference: Schema pitfalls to avoid (2026).
In parallel, citation selection behavior is becoming a first-class optimization target. Understanding how LLMs choose citations can inform how you structure pages (clear claims, explicit sources, stable URLs, and entity disambiguation).
Reference: How LLMs choose citations.
Operational GEO: citations, freshness, and provenance in agent-generated outputs
If your agents generate content (support macros, product docs, marketing pages), you need provenance: what source did the agent use, when was it last updated, and can a reviewer verify it quickly? This becomes more important as trust and privacy controversies shape user expectations about AI systems and data handling.
Example of broader trust pressure in AI search: Tom’s Guide coverage of Perplexity AI’s privacy controversy (user trust implications).
When agent harnesses are constrained, the winning strategy is to invest in reusable knowledge assets: canonical entity pages, structured data, and a governed retrieval layer. That reduces token spend (less redundant context), improves consistency, and increases the chance your content is cited correctly in generative answers.
Lessons Learned & Common Mistakes (E‑E‑A‑T): What We’d Do Differently Next Time
Most teams didn’t fail because they used agents—they failed because they optimized for speed of prototyping over durability. Here are the three recurring mistakes we see when subscription-backed harnesses are used as production infrastructure.
Mistake #1: Designing around subscription UI automation
UI automation is inherently brittle: DOM changes, bot detection, session expiry, and concurrency assumptions can break without notice. It also tends to blur user attribution (who initiated the action?)—a problem for both debugging and compliance.
Mistake #2: Ignoring governance (logs, RBAC, data boundaries)
If you cannot produce an audit trail (prompt → retrieval → tool calls → output → human approval), you will struggle to scale agentic workflows beyond a small team. This is especially true for agencies and enterprises where client separation and data retention are non-negotiable.
Mistake #3: Treating prompts as the system instead of the Knowledge Graph + workflow
Prompts are a UI. The system is your retrieval layer, your entity model, your evaluation harness, and your governance controls. Teams that externalize knowledge into a Knowledge Graph (entities, attributes, citations) and keep prompts lightweight tend to migrate faster and spend less on tokens.
Incident root-cause mix during migrations (illustrative template)
A template for categorizing failures observed during a harness → API migration. Replace values with your incident data.
Action Plan: Migration Playbook and Governance Checklist (30/60/90 Days)
A clean migration is less about swapping a model endpoint and more about rebuilding the workflow as a governed product: clear inputs/outputs, bounded autonomy, measurable success, and a stable knowledge layer. Use this phased plan to reduce risk while keeping delivery moving.
30 days: stopgap mitigations and risk reduction
Inventory harness dependencies and classify workflows by criticality (P0/P1/P2). Create fallbacks: native UI for human work; API for automation. Disable shared subscriber credentials and document data handling for each workflow (what data enters the model, where logs are stored, retention).
Define a minimal “agent contract” per workflow: inputs, allowed tools, max steps, max tokens, retry policy, and required citations/provenance fields.
60 days: API migration, orchestration, and Knowledge Graph integration
Migrate high-ROI workflows to API orchestration. Implement: per-user or per-client keys/projects, centralized logging, and a retrieval layer that pulls from canonical sources. Move “memory” out of the prompt into a durable store (entity-based notes, task state, and evidence summaries).
Add regression tests: fixed task suites, acceptance criteria, and budget thresholds (tokens/task, retries/task, latency). Treat prompt changes like code changes: versioning and staged rollout.
90 days: compliance hardening, cost optimization, and GEO measurement
Harden governance: RBAC, audit logs, retention, redaction, vendor risk review, and incident response. Optimize costs with context budgeting, retrieval summarization, caching, and loop constraints. For GEO, measure citation frequency in AI answers, AI referral traffic, and entity coverage in your Knowledge Graph.
KPI dashboard spec (sample)
Operational KPIs: completion rate (target >95%), mean retries/task (<0.3), p95 latency, $/completed task (within budget band), and incident rate. GEO KPIs: citation count in AI answers, AI referral sessions, retrieval success rate, and entity coverage (% of priority entities with canonical pages + structured data).
Key Takeaways
The Apr 4, 2026 change targets subscription-backed third‑party agent harnesses; API-based Claude usage is the durable path for automation.
The most impacted workflows are multi-agent orchestration, tool-using agents, and long-running jobs—especially when they relied on shared subscriber sessions.
API migration exposes hidden cost drivers (context bloat, retries, tool log verbosity); cost control requires budgets, caching, and bounded autonomy.
Governance becomes easier in an API-first architecture: per-user/per-client attribution, audit logs, RBAC, and retention policies are implementable.
GEO advantage shifts toward Knowledge Graph-first content infrastructure: canonical entities + structured data + provenance increase AI retrieval and citation reliability.
FAQ

Founder of Geol.ai
Senior builder at the intersection of AI, search, and blockchain. I design and ship agentic systems that automate complex business workflows. On the search side, I’m at the forefront of GEO/AEO (AI SEO), where retrieval, structured data, and entity authority map directly to AI answers and revenue. I’ve authored a whitepaper on this space and road-test ideas currently in production. On the infrastructure side, I integrate LLM pipelines (RAG, vector search, tool calling), data connectors (CRM/ERP/Ads), and observability so teams can trust automation at scale. In crypto, I implement alternative payment rails (on-chain + off-ramp orchestration, stable-value flows, compliance gating) to reduce fees and settlement times versus traditional processors and legacy financial institutions. A true Bitcoin treasury advocate. 18+ years of web dev, SEO, and PPC give me the full stack—from growth strategy to code. I’m hands-on (Vibe coding on Replit/Codex/Cursor) and pragmatic: ship fast, measure impact, iterate. Focus areas: AI workflow automation • GEO/AEO strategy • AI content/retrieval architecture • Data pipelines • On-chain payments • Product-led growth for AI systems Let’s talk if you want: to automate a revenue workflow, make your site/brand “answer-ready” for AI, or stand up crypto payments without breaking compliance or UX.
Related Articles

ChatGPT Optimization in 2026: A Working Checklist for Getting Your Brand Cited, Not Just Ranked
How ChatGPT retrieves and cites sources in July 2026, with a sourced Generative Engine Optimization checklist covering crawler access, extractable answers, entity signals, and measurement.

The EU Wants Google to Open Up Search Data to Rival AI Engines
EU plans to open Google Search data to rival AI engines. Learn why Structured Data—not raw click logs—will determine who can retrieve and cite the web.