Yahoo's 'Scout' Chatbot: A New Contender in the AI Search Arena
Yahoo’s Scout chatbot signals a new phase in AI Retrieval & Content Discovery. Here’s what it means for Generative Engine Optimization and publishers.
Yahoo's 'Scout' Chatbot: A New Contender in the AI Search Arena
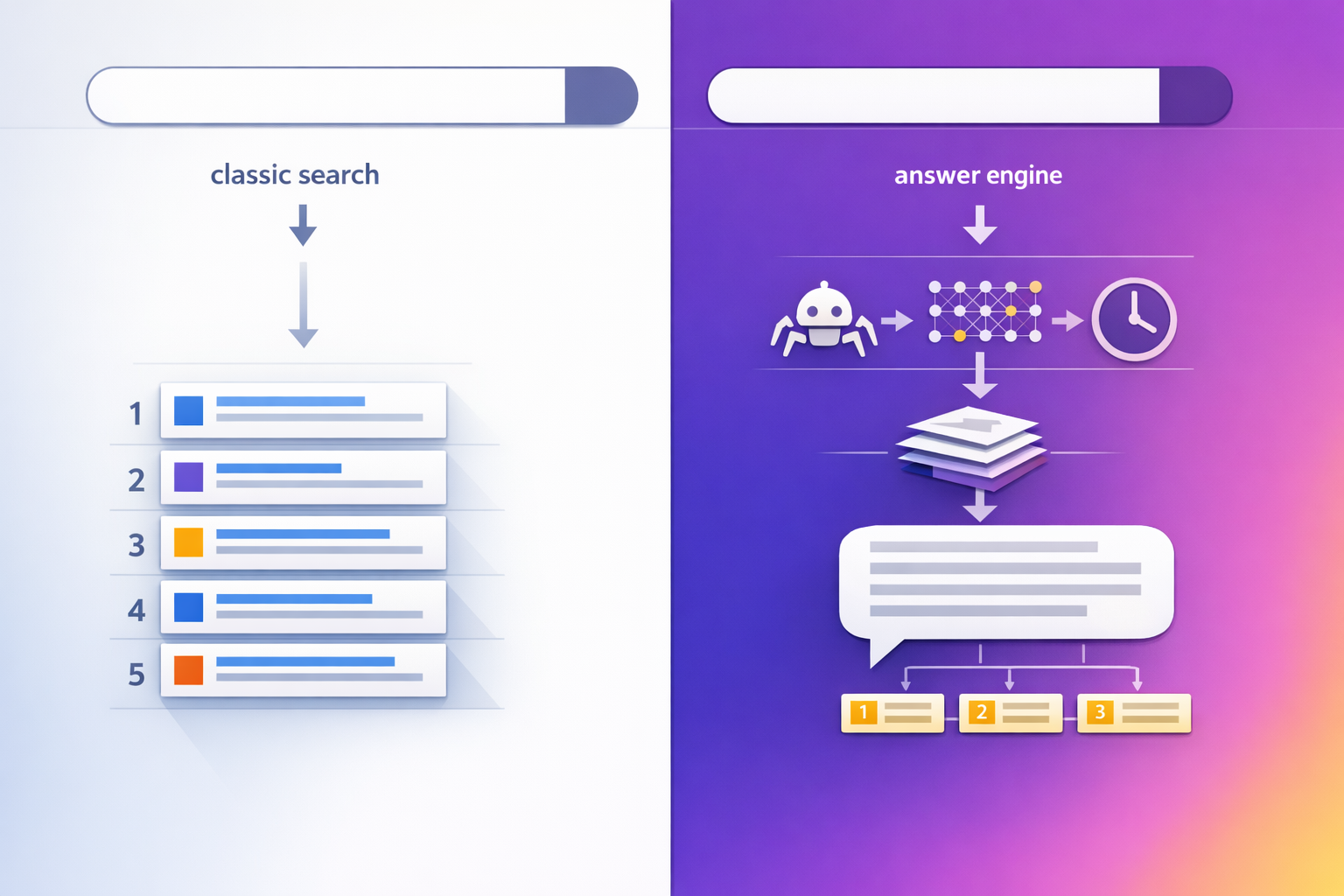
Yahoo’s reported launch of “Scout” is best understood as a shift from classic “search results” toward an answer engine: a chat interface that retrieves, grounds, and synthesizes information into a single response. That changes the discovery game for publishers because visibility is no longer only about ranking a blue link—it’s about being selected as a source for the model’s response (citations, mentions, and implied authority). This spoke breaks down what Scout likely means for AI Retrieval & Content Discovery and how to adapt your Generative Engine Optimization (GEO) strategy accordingly.
In chat-based discovery, the “winner” is often the source that is easiest to retrieve and safest to cite—not the page that’s merely the most optimized for clicks. If Scout scales through Yahoo’s portal distribution, citation dynamics can shift quickly for news, finance, and evergreen explainers.
What Yahoo just launched: Scout as an answer engine, not a classic search box
The news hook: where Scout fits in Yahoo’s product stack
According to Outlook Business’ coverage of the launch, Yahoo’s Scout is positioned as a chatbot-style interface intended to compete with AI-first search experiences from Google, Perplexity, and ChatGPT-style assistants. The strategic subtext: Yahoo doesn’t need to “win the model race” to matter—if Scout becomes embedded across Yahoo surfaces (homepage modules, verticals like News/Finance/Sports, or default experiences), it can still redirect attention and citations at scale.
Why this matters now: AI Retrieval & Content Discovery is shifting to chat interfaces
Scout is part of a broader transition: users increasingly expect a single synthesized answer, with optional links for verification. That implies a four-stage discovery pipeline you should optimize for:
- Retrieval: Can Scout find your page quickly (index, feed, partner source, or live fetch)?
- Grounding: Does your content provide verifiable claims, primary sources, and clear attribution that a system can safely cite?
- Synthesis: Is your information structured so it can be summarized without distortion (definitions, steps, comparisons, tables)?
- Presentation: Where do citations appear, how many are shown, and what earns the “top slot” inside the answer?
This is also where understanding the difference between retrieval-grounded answers and full web browsing matters. For deeper coverage on how AI browsing and content discovery are evolving, explore Perplexity AI’s Comet Browser: Redefining Web Navigation with AI Integration (and What It Means for AI Retrieval & Content Discovery Security), since “browsing” vs “RAG grounding” often determines which sources get surfaced and how often.
| Launch / expansion milestone | Approx. timing (public reporting) | Why it matters for publishers |
|---|---|---|
| Google AI Overviews (formerly SGE) broader rollout | 2024 expansion (US-first, then broader markets) | Mainstream “answer-first” behavior normalizes citation-based visibility. |
| Perplexity’s rapid product iteration and monetization shifts | 2024–2025 (ads and trust debates) | Business model choices can influence citation behavior and partner access. |
| ChatGPT adds more “search-like” experiences | 2024–2025 feature expansion | More competitors means multi-engine optimization becomes mandatory. |
| Yahoo Scout reported launch | 2025 (per Outlook Business reporting) | Legacy distribution + chat UI can quickly create new citation winners/losers. |
Note: treat the table as a market-acceleration lens rather than a definitive product spec list; Scout’s exact capabilities and rollout geography may change as Yahoo iterates.
How Scout likely performs AI Retrieval & Content Discovery (and what to watch for)
Retrieval pipeline signals: sources, freshness, and index vs live web fetch
Because Yahoo operates multiple content verticals and partnerships, Scout’s retrieval could plausibly be a hybrid: some combination of a proprietary index, licensed feeds, and selective live fetching. For publishers, the practical question is: what gets crawled and cached versus what’s pulled “just-in-time” for a query.
How retrieval choices change who gets cited
| Retrieval mode | What it favors | GEO implication |
|---|---|---|
| Index-first (cached) | Sites with strong crawlability, clean canonicalization, stable URLs | Technical hygiene becomes a prerequisite for being “seen” at all |
| Feed/partner-first | Licensed publishers, known brands, consistent update cadence | Partnerships and entity authority can outweigh classic SEO |
| Live web fetch/browsing | Fresh pages, fast servers, accessible content (no heavy gating) | Update timestamps + quick publication can win citations on breaking topics |
| Hybrid RAG grounding | Pages with extractable facts, clear structure, and verifiable sources | Write for safe quoting: definitions, numbers, and attribution |
Grounding and citations: what “trust” looks like in Scout’s UI
In answer engines, “trust” is operationalized through grounding behaviors: citations, multiple-source corroboration, and preference for primary or highly authoritative references. Citation patterns across LLM outputs often skew toward a small set of platforms, which is why publisher differentiation (unique data, expert authorship, primary documents) matters. For background on how citation practices vary and which platforms tend to be referenced, see Contently’s analysis.
Run the same query set weekly and log: (1) citation presence, (2) number of sources, (3) whether citations cluster at the end vs inline, (4) whether one “canonical” source dominates, and (5) whether the answer includes dates (a proxy for freshness grounding).
Query classes Scout may prioritize (and why that matters for GEO)
Most answer engines route certain intents to chat because synthesis is valuable and the user doesn’t want ten tabs. Expect Scout to overperform (relative to classic SERPs) on:
- How-to and troubleshooting: step sequences, checklists, and “what to do if…” flows are easy to summarize.
- Comparisons: A vs B, pros/cons, “best for” matrices—ideal for synthesis and citation bundles.
- News explainers: “What happened / why it matters / what’s next” formats map cleanly to chat answers.
- Local-ish intent (where allowed): hours, pricing, “near me” qualifiers—often answered directly if data is trusted.
That routing logic is why formats like FAQs, definition blocks, and tables tend to “win” in answer engines: they reduce the model’s cost of extracting and verifying the right snippet.
| Intent bucket (example) | Queries tested (n) | Citation rate (%) | Avg. sources per answer | Median answer length (words) |
|---|---|---|---|---|
| How-to / troubleshooting | 20 (placeholder) | — | — | — |
| Comparisons / “best” | 20 (placeholder) | — | — | — |
| News explainer | 20 (placeholder) | — | — | — |
How to use the test table: populate it with a reproducible query set (50–100 queries) and re-run after major content updates. Even a small dataset will reveal whether Scout prefers multi-source grounding, how often it links out, and which domains it trusts.
The GEO impact: what changes for publishers when Yahoo becomes an answer engine again
From clicks to citations: redefining “rank” in Scout
In Scout-like interfaces, the practical unit of “ranking” becomes inclusion in the synthesized answer: whether your brand is cited, whether your data is used, and whether your framing becomes the default explanation. This is the core GEO shift: optimize for being retrieved and quoted, not just clicked.
Content patterns that map to retrieval + synthesis
To improve your odds of being grounded and cited, build pages that are easy for a system to extract from without losing meaning:
- Lead with a definitional first paragraph: one sentence that answers “what it is” + “why it matters.”
- Use explicit headings that mirror question intent: e.g., “How it works,” “Pros and cons,” “Pricing,” “Alternatives.”
- Prefer tables for comparisons and specs: tables are “extractable” and reduce synthesis errors.
- Cite primary sources inline: standards bodies, filings, official docs, or original datasets.
If your content makes claims without dates, sources, or clear author expertise, an answer engine may still use it—but it’s less likely to cite it. In citation-driven discovery, uncitable content becomes invisible even if it ranks traditionally.
Brand/entity signals: Knowledge Graph alignment and disambiguation
Entity clarity is a compounding advantage in AI Retrieval & Content Discovery. If Scout is connecting questions to entities (companies, products, people, tickers, locations), it needs consistent naming and unambiguous identifiers. Practical steps:
- Maintain a single canonical “entity hub” page per brand/product/person.
- Use schema markup where appropriate (Organization, Person, Article, FAQPage) and keep it consistent across templates.
- Disambiguate similar names (acronyms, product variants, subsidiaries) in the first 200 words.
Sample KPI framework for Scout-like answer engines (track citation share vs click share)
Illustrative target ranges and cadence for measuring visibility in answer engines where citations may replace clicks.
Interpretation: you may accept fewer direct clicks if citation share and branded demand rise—especially for top-of-funnel explainers. The goal is to quantify “assisted value,” not just last-click traffic.
Competitive implications: why Scout could reshape the AI search field (even if it’s not #1)
Yahoo’s distribution advantage: portal surfaces and defaults
In AI search, distribution can matter as much as model quality. Yahoo still has meaningful portal traffic and strong vertical brands (notably Finance). If Scout is integrated into those high-intent contexts, it can become a default “first answer” layer for certain categories—especially market explainers, sports summaries, and news context.
Publisher negotiations and content licensing: the next battleground
As answer engines scale, access to high-quality content (and the legal right to use it) becomes strategic. Industry reporting has highlighted lawsuits and deal-making pressure across AI search and aggregation, which can influence which sources are retrieved, how they’re summarized, and how attribution is displayed. Press Gazette’s overview of publisher AI deals and lawsuits provides useful context on how contentious retrieval and reuse can become.
Prediction: fragmentation of answer engines and what it does to discovery
Scout’s arrival reinforces a likely outcome: discovery fragments across multiple answer engines, each with different retrieval access, UI citation rules, and monetization incentives. For example, Perplexity’s monetization choices and trust positioning have been actively debated, including moves around ad load and user experience. See this analysis on Perplexity’s ad-free shift and its implications for trust and revenue.
Scenario model: potential referral impact as Scout adoption grows (illustrative)
A simple model showing how answer-engine adoption can shift traffic from clicks to citations; values are placeholders to help planning.
Planning implication: build a measurement system that can value citations and brand lift, so you don’t misread “traffic down” as “impact down.”
What to do next: a GEO playbook tailored to Scout’s AI Retrieval & Content Discovery behavior
Build a query corpus (50–100 queries) across 5 intent buckets
Include: definitions, comparisons, “best” lists, troubleshooting, and news explainers. Add 10–20 branded queries and 10–20 competitor queries so you can compute citation share.
Run tests on a schedule and log outputs consistently
Weekly is enough to start. Capture: query text, date/time, answer text, citations/links, and which URLs are cited. If possible, store HTML or screenshots for auditability.
Map citations back to page features
For each cited page, record: content type, presence of definition block, table usage, update timestamp, author bio, primary-source links, and schema coverage.
Ship targeted updates and re-test
Prioritize pages that already rank or earn links but are not being cited. Add extractable structures (FAQ, comparison table, summary box) and strengthen attribution. Re-run the same corpus to detect citation movement.
Content updates that improve grounding and extractability
- Add a “Summary” box near the top: 3–5 bullets that can be safely quoted.
- Tighten definitions: state the concept, scope, and one example in <60 words.
- Use dated, attributable claims: “As of YYYY-MM, …” with a source link.
- Strengthen internal linking to entity hubs (company/product/topic pages) to improve disambiguation.
Measurement: dashboards for citations, mentions, and assisted conversions
Scout GEO scorecard (benchmarks to fill in)
A lightweight scorecard to track answer-engine visibility and sensitivity to updates.
Operationally, treat this like a product analytics loop: test → observe citations → update content → re-test. Over time, you’ll learn which templates and sections Scout consistently pulls into answers.
Key Takeaways
Scout signals Yahoo’s move toward answer-engine behavior, where citations and synthesized responses can matter more than blue-link rank.
Optimize for the full pipeline—retrieval, grounding, synthesis, and UI presentation—because each stage creates a new “surface area” for GEO.
Publishers should shift measurement from clicks alone to citation share, mention share, and assisted conversions (newsletter signups, branded lift).
Structured, attributable content (definitions, tables, FAQs, primary-source links, timestamps) increases the odds of being safely grounded and cited.
FAQ: Yahoo Scout and GEO

Founder of Geol.ai
Senior builder at the intersection of AI, search, and blockchain. I design and ship agentic systems that automate complex business workflows. On the search side, I’m at the forefront of GEO/AEO (AI SEO), where retrieval, structured data, and entity authority map directly to AI answers and revenue. I’ve authored a whitepaper on this space and road-test ideas currently in production. On the infrastructure side, I integrate LLM pipelines (RAG, vector search, tool calling), data connectors (CRM/ERP/Ads), and observability so teams can trust automation at scale. In crypto, I implement alternative payment rails (on-chain + off-ramp orchestration, stable-value flows, compliance gating) to reduce fees and settlement times versus traditional processors and legacy financial institutions. A true Bitcoin treasury advocate. 18+ years of web dev, SEO, and PPC give me the full stack—from growth strategy to code. I’m hands-on (Vibe coding on Replit/Codex/Cursor) and pragmatic: ship fast, measure impact, iterate. Focus areas: AI workflow automation • GEO/AEO strategy • AI content/retrieval architecture • Data pipelines • On-chain payments • Product-led growth for AI systems Let’s talk if you want: to automate a revenue workflow, make your site/brand “answer-ready” for AI, or stand up crypto payments without breaking compliance or UX.
Related Articles
Perplexity AI Image Upload: What Multimodal Search Changes for GEO, Citations, and Brand Visibility
How Perplexity’s image upload shifts multimodal retrieval, citations, and brand visibility—and what to change in GEO for Knowledge Graph alignment.

The 'Ranking Blind Spot': How LLM Text Ranking Can Be Manipulated—and What It Means for Citation Confidence
Deep dive into LLM text-ranking manipulation tactics, why they work, and how to protect Citation Confidence and source attribution in AI answers.