Perplexity's Sonar Pro API: Advancing Real-Time Search with Enhanced Citation Architecture (Comparison Review)
Compare Perplexity Sonar Pro API vs alternatives for real-time search and citation architecture—latency, freshness, traceability, and Knowledge Graph grounding.
Perplexity's Sonar Pro API: Advancing Real-Time Search with Enhanced Citation Architecture (Comparison Review)
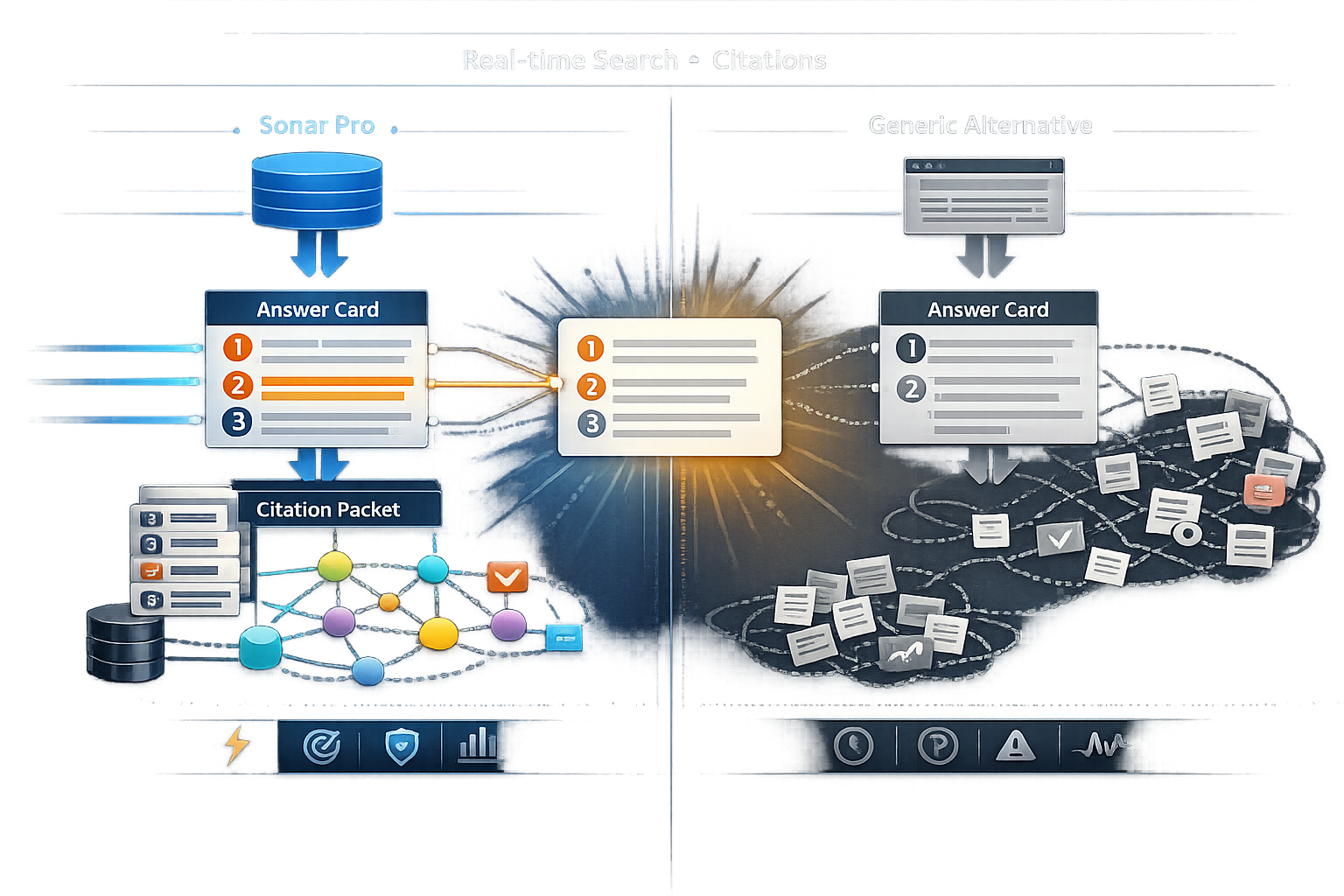
Perplexity’s Sonar Pro API is best understood as a real-time search + answer interface where citations are a first-class output—not a UI detail added later. That matters because in AI search, citations aren’t just “links”; they’re the audit trail that lets users, compliance teams, and downstream systems verify what the model claims. In this comparison review, we’ll define what “enhanced citation architecture” means, show how to evaluate Sonar Pro against common alternatives (LLM browsing tools and curated RAG), and outline an implementation pattern for turning citations into reusable evidence for Knowledge Graph grounding and GEO workflows.
For context on how AI search competition is reshaping retrieval, grounding, and citation expectations, see our comparison brief on OpenAI's GPT-5.2 Release: A New Contender in the AI Search Arena, and how search quality signals are evolving in our analysis of the Google Algorithm Update March 2025. Both help frame why citation traceability is becoming a competitive differentiator in AI answers.
Citation architecture = the end-to-end system that (1) selects sources, (2) attaches provenance signals (what was retrieved, when, and why), and (3) renders citations so a human or auditor can verify each factual claim.
What “enhanced citation architecture” means for real-time AI search (and why Sonar Pro is different)
Featured snippet: Definition + evaluation criteria (freshness, traceability, coverage, stability)
“Enhanced citation architecture” in real-time AI search usually implies more than “the answer includes links.” It means citations are structured enough to support verification, reproducibility, and downstream reuse (e.g., evidence stores or Knowledge Graphs). For a practical review, evaluate citation architecture on four criteria:
- Freshness: How recent are cited sources relative to the query? (e.g., % of sources published/updated in last 7 days).
- Traceability: Can you map claims to sources (inline/claim-level) vs generic “further reading” links?
- Coverage: What fraction of factual claims are cited (cited claims / total factual claims)?
- Stability: Do citations persist (low broken-link rate), and do the “top citations” drift dramatically over time for the same query?
Sonar Pro’s differentiator (as positioned in industry coverage) is treating these citation outputs as part of the product surface—optimized for real-time retrieval and automated citation generation—rather than leaving teams to “bolt on” provenance later.
| Criterion (0–5) | What to measure | Example benchmark metric | Why it matters for GEO/KG |
|---|---|---|---|
| Freshness | Source age distribution and retrieval time | % sources < 7 days (20-query set) | Improves “new info” discovery and timely entity updates |
| Granularity | Domain vs page vs passage-level citations | % passage-level citations | Enables claim-to-evidence edges for Knowledge Graph grounding |
| Coverage | Whether each factual claim is cited | Cited claims / total factual claims | Reduces hallucination risk and raises citation confidence |
| Stability | Broken links + citation drift over time | Broken-link rate after 30 days; drift rate (14-day retest) | Supports reproducibility and audit logs |
How citations connect to Knowledge Graph grounding in retrieval pipelines
In modern retrieval pipelines, citations can be treated as evidence objects: each citation is an “edge” that links an answer claim to a source, and—if you extract entities and attributes—an edge that connects entity nodes to supporting documents. Over time, repeated citations form patterns that help you: (1) resolve entity ambiguity (which “Acme” is this?), (2) prioritize authoritative sources, and (3) build a semantic network of claims grounded in verifiable references.
This is also why citation behavior matters for AI visibility: analyses of large citation sets show that content structure and clarity influence whether models cite you. See: Building Citation-Worthy Content: Strategies for Enhancing AI Visibility.
Sonar Pro API: citation outputs, provenance signals, and how they map to Knowledge Graph needs
Citation granularity: domain/page/passage and claim-to-source alignment
When evaluating Sonar Pro responses, inspect citations like you would inspect logs in a production system. Specifically, look for: (1) number of citations per answer, (2) whether citations are inline (near the claim) versus a footer list, and (3) whether you can reliably align each factual claim to at least one citation. The closer you get to passage-level grounding (rather than domain-level), the easier it is to build “claim → evidence” edges in a Knowledge Graph and to debug failures.
Provenance metadata: timestamps, source types, and confidence cues
Provenance signals are the difference between “a link” and “evidence.” For Knowledge Graph workflows, the most useful signals to capture per citation are:
- Retrieval timestamp: When the system fetched/considered the source (critical for audits).
- Publication/updated date (when available): Supports freshness scoring and time-scoped claims.
- Source type/category: Primary source, official docs, news, blog, forum, etc. (for authority filters).
- Canonical URL and publisher identity: Reduces duplication and improves entity resolution.
Failure modes: missing citations, over-citation, and citation drift
Real-time systems fail in predictable ways. Three that matter operationally:
- Missing citations: The answer contains factual assertions without any supporting links (coverage failure).
- Over-citation: Too many citations for too few claims, often indicating weak claim-to-source alignment (hard to audit).
- Citation drift: The same query yields different citations across time due to index changes, ranking shifts, or content churn—great for freshness, risky for reproducibility.
If you need reproducibility, treat “query + time + citations” as a versioned artifact. Store the full citation set, retrieval timestamp, and canonical URLs so you can re-run audits even when the live web changes.
Example: Citation drift tracking over 14 days (same query set)
Illustrative trend showing how the share of “new” citations can change over time in real-time retrieval systems. Use this to quantify drift and set acceptable thresholds for your use case.
To ground your evaluation in real usage, you can build a small benchmark (10–30 queries) and score: citation coverage rate, passage-level share, freshness window, and drift. Industry discussion around Sonar Pro emphasizes real-time search with automated citation generation; see: Perplexity's 'Sonar Pro' API: Advancing Real-Time Search with Enhanced Citation Architecture.
Side-by-side comparison: Sonar Pro vs alternative real-time search + citation approaches
Comparison table: Sonar Pro vs “LLM + web search tool” vs “RAG over curated index”
High-level tradeoffs (what you get vs what you control)
| Approach | Strengths | Limitations | Best for |
|---|---|---|---|
| Sonar Pro (real-time search API with citations) | Fast integration; citations as standardized output; strong for discovery and freshness | Less deterministic; drift requires logging/versioning; source set may be broader than “approved-only” | Market/news monitoring, GEO teams, rapid research with traceability |
| General LLM + web search/browsing tool | Flexible; good for exploratory tasks; can find long-tail sources | Citation stability and formatting can be inconsistent; harder to audit at scale | Ad-hoc research, low-risk internal use, early ideation |
| RAG over curated index + custom citation renderer | Maximum controllability; deterministic source allowlists; internal docs + policy-compliant citations | Higher engineering cost; freshness limited by crawl/ingest; you own citation QA | Regulated domains, support knowledge bases, enterprise compliance workflows |
Where each approach wins: compliance, latency, freshness, controllability
A practical way to decide is to benchmark the same query set across approaches and score four outputs: latency (p50/p95), freshness (median source age), citation density (citations per answer), and human-rated traceability (1–5). Below is an example of how to visualize results once you run your own test.
Example benchmark view (10–30 identical queries across approaches)
Illustrative comparison of traceability score and median source age. Replace with your measured results.
Knowledge Graph implication in one sentence: curated RAG can enforce ontology constraints more tightly, while Sonar Pro can accelerate evidence collection and entity updates when freshness is the bottleneck. If your visibility depends on being cited accurately, your evaluation should also include how consistently each approach produces citations that are easy to parse, normalize, and store.
If you can’t reproduce the citation set for a high-impact answer, you don’t really have “grounding”—you have a snapshot.
Implementation pattern: using Sonar Pro citations to strengthen AI Citation Patterns and Knowledge Graph workflows
Pipeline diagram: retrieval → citation normalization → evidence store → Knowledge Graph edges
The most reliable implementation pattern is to treat Sonar Pro citations as structured evidence objects, not just strings. You add a normalization layer, then store citations in an evidence table (or document store), and only then update a Knowledge Graph. This reduces duplication, improves stability, and makes audits feasible.
| Stage | Input | Output you store | Why it helps |
|---|---|---|---|
| Retrieval | Query + Sonar Pro response | Raw citations + retrieval timestamp | Preserves the original evidence snapshot |
| Normalization | URLs, titles, snippets/passages | Canonical URL, publisher ID, passage hash | Reduces duplicates and improves link stability |
| Evidence store | Normalized evidence objects | Evidence IDs + metadata for audit | Enables re-validation and reuse across answers |
| KG update | Entity/claim extraction + evidence IDs | Edges: (entity) —supported_by→ (evidence/source) | Makes provenance explicit and queryable |
Normalization rules: canonical URLs, passage hashing, and source deduplication
Canonicalize URLs
Strip tracking parameters (UTM, gclid), resolve redirects, and store both the original URL and the canonical URL (when available). Use canonical tags where possible, and keep a redirect chain for audits.
Deduplicate by publisher identity
Normalize publisher names (e.g., “NYTimes” vs “The New York Times”) and map to a stable publisher ID. This improves source diversity scoring and prevents single-network dominance.
Hash passages/snippets
If you receive a snippet/passage, compute a passage hash (e.g., normalized text + SHA-256). This lets you detect when “the same citation” changes content over time (quiet edits) and track evidence reuse.
Store retrieval context
Log query, model/version (if available), retrieval time, and full citation list. For high-risk topics, schedule re-validation (e.g., weekly) and alert on drift beyond a threshold.
For governance patterns and risk framing, NIST’s AI RMF is a useful reference point (especially for traceability and monitoring): https://www.nist.gov/itl/ai-risk-management-framework. For structured data and canonicalization best practices that directly affect citation stability, see Google’s guidance on canonical URLs: https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls.
Recommendation: when to choose Sonar Pro for citation-forward real-time search (and when not to)
Best-fit scenarios: GEO teams, analysts, and content ops needing verifiable freshness
- Choose Sonar Pro when freshness + verifiable citations are the product requirement. Examples: market intel, newsroom research, competitive monitoring, and GEO workflows where you need to see what sources AI systems are likely to surface and cite.
- Choose Sonar Pro when integration speed matters. If your alternative is building a full retrieval stack + citation renderer, Sonar Pro can reduce time-to-first-auditable-answer.
Not-best-fit: strict walled-garden sources, deterministic citations, or heavy ontology enforcement
- Prefer curated RAG when you must guarantee only approved sources (allowlists), require deterministic citation sets, or need strict ontology enforcement before any claim is stored.
- Avoid real-time-only citation dependency for high-risk claims without an evidence store. If you don’t persist citations, you can’t audit them later.
Decision matrix (example weights by persona)
Illustrative weighted priorities. Use this to score Sonar Pro vs alternatives based on what your stakeholders value most.
Ask a search relevance engineer: “What drift rate is acceptable before we treat an answer as non-reproducible?” Ask a Knowledge Graph architect: “What provenance fields are mandatory for an evidence edge?” Ask a newsroom standards editor: “What citation transparency is required to publish AI-assisted research?”
Key Takeaways
Enhanced citation architecture is measurable: evaluate freshness, traceability (claim-to-source), coverage (cited claims), and stability (broken links + drift).
Sonar Pro is strongest when you need real-time discovery with citations as a standardized output—especially for GEO and evidence collection workflows.
To make real-time citations auditable, version them: store query + retrieval timestamp + canonical URLs + passage hashes to manage drift.
For regulated or allowlist-only requirements, curated RAG still wins on controllability—even if it’s slower to build and less fresh.
FAQ
Additional context on Perplexity’s broader push into AI-assisted navigation and integrations can be found in coverage of its browser and ecosystem moves, which helps explain why real-time retrieval + citations are becoming central to product strategy: https://www.crescendo.ai/news/latest-ai-news-and-updates and https://www.techradar.com/phones/samsung-galaxy-phones/theres-possibility-for-another-partner-to-join-the-ecosystem-as-perplexity-lands-on-samsung-galaxy-s26-phones-a-samsung-head-is-already-teasing-the-next-ai-addition.

Founder of Geol.ai
Senior builder at the intersection of AI, search, and blockchain. I design and ship agentic systems that automate complex business workflows. On the search side, I’m at the forefront of GEO/AEO (AI SEO), where retrieval, structured data, and entity authority map directly to AI answers and revenue. I’ve authored a whitepaper on this space and road-test ideas currently in production. On the infrastructure side, I integrate LLM pipelines (RAG, vector search, tool calling), data connectors (CRM/ERP/Ads), and observability so teams can trust automation at scale. In crypto, I implement alternative payment rails (on-chain + off-ramp orchestration, stable-value flows, compliance gating) to reduce fees and settlement times versus traditional processors and legacy financial institutions. A true Bitcoin treasury advocate. 18+ years of web dev, SEO, and PPC give me the full stack—from growth strategy to code. I’m hands-on (Vibe coding on Replit/Codex/Cursor) and pragmatic: ship fast, measure impact, iterate. Focus areas: AI workflow automation • GEO/AEO strategy • AI content/retrieval architecture • Data pipelines • On-chain payments • Product-led growth for AI systems Let’s talk if you want: to automate a revenue workflow, make your site/brand “answer-ready” for AI, or stand up crypto payments without breaking compliance or UX.
Related Articles

Truth Social’s AI Search: Balancing Information and Control
Truth Social’s AI search will shape what users see and cite. Here’s how Structured Data can improve transparency—without becoming a tool for control.

LLM Citations vs. Google Rankings: Unveiling the Discrepancies
Compare why LLMs cite different sources than Google ranks. Learn criteria, patterns, a comparison table, and how to measure AI Visibility reliably.