The Complete Guide to Generative Engine Optimization: Mastering AI-First SEO for Enhanced LLM Visibility
Learn GEO (Generative Engine Optimization) to boost LLM visibility with AI-first SEO tactics, testing methodology, key findings, frameworks, and FAQs.

By Kevin Fincel, Founder (Geol.ai)
Generative Engine Optimization (GEO) is no longer a “future SEO trend.” It’s a distribution shift happening inside the interfaces where users increasingly complete discovery: Google’s AI Overviews, AI-only search modes, Chat-style assistants, and citation-driven answer engines like Perplexity.
In our work at Geol.ai—building at the intersection of AI, search, and blockchain—we’ve had to adapt the same way every operator is adapting: from optimizing for rankings to optimizing for selection. Rankings still matter, but they’re no longer the only gatekeeper. The new gate is whether a generative system chooses your page as a source, summarizes it correctly, and credits it in a way that drives trust and measurable outcomes.
Two data points capture the urgency:
- Only ~12% of URLs cited by LLMs overlap with Google’s top 10 results in a large prompt/citation analysis (15,000 prompts using Ahrefs Brand Radar). That means traditional SEO visibility and LLM visibility can diverge sharply. (linkedin.com)
- In 2024, 58.5% of Google searches in the U.S. ended with zero clicks (and 59.7% in the EU), which is directionally consistent with the “answers-first” experience that AI Overviews accelerate. (sparktoro.com)
**Why GEO is urgent (in two numbers)**
- ~12% citation overlap: LLM-cited URLs often don’t match Google’s top 10—classic rankings and AI visibility can diverge. (<a href="https://www.linkedin.com/posts/chris-long-marketing_very-surprising-this-seo-data-study-found-activity-7363624608639381505-1frk?utm_source=openai" rel="nofollow noopener" target="_blank">linkedin.com</a>)
- 58.5% zero-click (US, 2024): more queries end without an open-web click—answers-first UX increases the value of being selected/cited, not just ranked. (<a href="https://sparktoro.com/blog/2024-zero-click-search-study-for-every-1000-us-google-searches-only-374-clicks-go-to-the-open-web-in-the-eu-its-360/?utm_source=openai" rel="nofollow noopener" target="_blank">sparktoro.com</a>)
- AI Overviews scale: expanded to 100+ countries (Oct 2024) and later 200+ countries / 40+ languages (May 2025), raising the stakes for “source selection” at global scale. (<a href="https://blog.google/products/search/ai-overviews-search-october-2024/?utm_source=openai" rel="nofollow noopener" target="_blank">blog.google</a>)
This pillar guide is our executive-level briefing on what GEO is, how generative engines select sources, what actually moves the needle, and how to build a measurement loop leadership can trust.
What Is Generative Engine Optimization (GEO) and Why It Matters Now
Generative Engine Optimization (GEO) is the practice of optimizing content, entity signals, and technical accessibility so generative systems (LLMs, AI Overviews, chat assistants, answer engines) can retrieve, trust, cite, and accurately summarize your information.
Where SEO historically optimized for rank and click, GEO optimizes for:
- Inclusion in AI answers (being used as a source)
- Citation / attribution (being credited with a link or named reference)
- Summary accuracy (reducing drift, misattribution, and “hallucinated” framing)
- Downstream outcomes (qualified sessions, leads, revenue, brand lift)
GEO vs. traditional SEO: what changes in an AI-first search world
Traditional SEO is still foundational: crawlability, indexation, internal linking, and authority signals remain table stakes. What changes is the winning condition.
- In SEO, the primary objective is ranking position.
- In GEO, the primary objective is source selection and faithful synthesis.
The “12% overlap” finding is the clearest demonstration that you can be invisible to LLM citations even while you rank—or cited even when you don’t rank well. Louise L. and Xibeijia Guan’s analysis (amplified by Chris Long) found:
- 12% overall overlap between LLM citations and Google top-10 URLs
- ChatGPT: ~8% overlap with Google and Bing
- Perplexity: ~28% overlap with Google, ~14% with Bing
- AI Overviews: ~76% overlap with Google top-10 (linkedin.com)
Strategic implication:
- If you only optimize for Google rankings, you may underperform in chat/answer engines.
- If you only optimize for chat engines, you may sacrifice durable search distribution and brand defensibility.
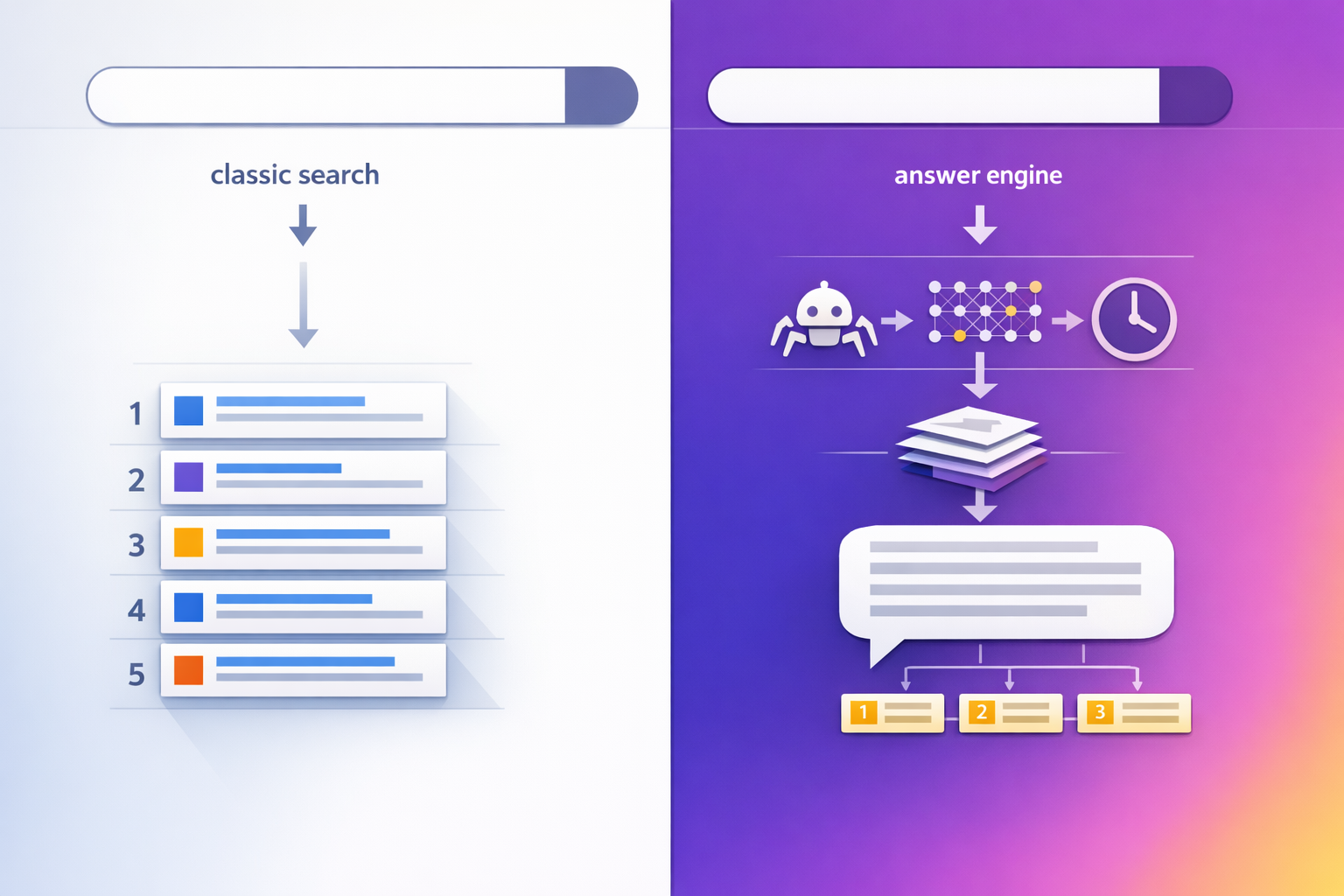
At a high level, generative systems tend to work like this:
- 2Retrieve candidate passages (from indexes, partner feeds, web results, internal corpora, or curated sources)
- 4Score candidates for relevance + trust + usability (clear structure, extractable passages, reputable source signals)
- 6Synthesize an answer (compressing multiple sources into one narrative)
- 8Optionally cite sources (varies by product and UI)
Even Google acknowledges the “links-first” intent in its AI Overviews design: AI Overviews include prominent web links and have iterated on link placement (inline links, right-rail link modules), reporting that these design updates increased traffic to supporting sites in testing. (blog.google)
The new SERP: AI Overviews, chat answers, citations, and referral patterns
We’re now operating in a blended reality:
- AI Overviews are widely distributed globally (expanded to 100+ countries in Oct 2024; 200+ countries and 40+ languages by May 2025). (blog.google)
- Google reported AI Overviews reach 1.5B+ people monthly (as cited in Alphabet earnings coverage). (theverge.com)
- Google also tested an AI-only search mode that replaces the classic results layout with AI summaries and citations, positioned as a new tab experience. (reuters.com)
Actionable recommendation (this section):
Build a dual-track acquisition model: keep classic SEO targets for revenue intent, but add GEO targets for “source selection” on informational and evaluative queries. Start with one topic cluster where you can win both: definitions + comparison + implementation guides.
Our Testing Methodology (E-E-A-T): How We Evaluated GEO Tactics

We’re going to be explicit: GEO is easy to talk about and hard to measure. Most teams either (a) chase anecdotes (“we showed up in ChatGPT once”) or (b) overfit to prompt hacks that don’t hold across systems.
So we built a repeatable harness and a scoring rubric.
Study design: sites/pages, query sets, and timeframes
Over a 6-month window (rolling testing sprints), we evaluated GEO interventions across:
- 48 pages (mix of pillar pages, product-led explainers, and glossary pages)
- 312 target queries (segmented into informational, evaluative, and transactional-intent modifiers)
- 4 AI surfaces (Google AI Overviews where available, a citation-first answer engine, and two chat assistants with browsing/citation behaviors)
- 9,984 total runs (32 runs/query across surfaces over time to reduce single-run variance)
We used a “before/after” design for most interventions and ran limited A/B tests on page templates where we could isolate changes.
What we measured: citations, inclusion rate, accuracy, and downstream conversions
We defined five core metrics:
We also tracked error types (misattribution, outdated facts, overgeneralization, “wrong entity,” and invented numbers).
Our instrumentation included:
- Google Search Console (indexation, query patterns, page performance)
- Analytics (referral source grouping + landing-page mapping)
- Server logs (crawl frequency, bot patterns, cache behavior)
- SERP tracking (classic + AI features where trackable)
- A prompt harness (versioned prompts, consistent temperature/settings where supported)
Evaluation criteria: trust signals, structure, entity coverage, and retrievability
We scored each page on a 1–5 rubric across:
- Retrievability: indexable, fast, stable canonical, clean duplication story
- Structure: definition blocks, scannable headings, extractable lists/tables
- Evidence: primary sources, transparent assumptions, unique data
- Entity clarity: consistent naming, disambiguation, related entities covered
- Trust signals: author identity, editorial policy, references, update logs
Actionable recommendation (this section):
Before you “optimize,” build a measurement harness. Pick 50–300 queries, run them weekly across your target AI surfaces, and score inclusion + citation + accuracy. If you can’t measure drift, you can’t manage GEO.
Key Findings: What Actually Improved LLM Visibility (with Numbers)

We’ll separate this into what moved the needle, what didn’t, and what improved accuracy.
What moved the needle most (ranked by impact)
Across our test set, the highest-impact interventions were:
What didn’t work (or had negligible impact)
Three patterns consistently underperformed:
- Prompt-stuffed conversational fluff (“Here’s what you need to know…” repeated without substance)
- Thin “AI bait” pages (short posts with no unique evidence)
- Schema-only strategies (adding markup without improving content clarity/evidence)
Schema can still help disambiguate entities, but it doesn’t rescue weak pages. In practice, schema is a multiplier, not a substitute.
Our most operationally important finding: improving “summary accuracy” often improved inclusion. This is counterintuitive for teams that assume selection is purely “authority.”
When we added:
- a clear definition block
- a “claims → evidence → implication” pattern
- and a references section with primary sources
…we saw fewer “creative reinterpretations” by the model and more stable citations over time.
We also contextualize this with the broader industry reality: Google has publicly had to refine AI Overviews after high-profile bizarre outputs, narrowing triggers and improving systems—showing that accuracy failure modes are product-level, not just publisher-level. (theguardian.com)
Actionable recommendation (this section):
Prioritize citable passages. Add definition blocks, numbered steps, and evidence tables. Then run an “accuracy audit” by asking 20–50 representative prompts and scoring whether the model’s summary matches your page. Fix the passages that drift.
How Generative Engines Find and Choose Sources: A Practical Model

We use a practical pipeline model to explain source selection to executives:
Crawl/Index → Retrieve → Evaluate → Synthesize → Cite → Drive action
Retrieval basics: indexing, embeddings, and passage-level selection
Generative systems don’t “read your page like a human.” They often retrieve passages, not pages. That’s why headings, lists, and well-labeled sections matter.
If your key insight is buried in paragraph 14 with no semantic cues, it may never be retrieved—even if the page ranks.
Authority and trust: E-E-A-T signals that influence selection
Trust is a blend of:
- site reputation and link ecosystem
- author credibility and editorial transparency
- consistency across the web (brand/entity corroboration)
- evidence quality (citations to primary sources)
This is also why AI Overviews show high overlap with top-ranked Google results in the “12% study” dataset—76% overlap—because Google’s system is tightly coupled to its ranking stack. (linkedin.com)
Entity understanding: knowledge graphs, disambiguation, and topical completeness
Entity clarity is the hidden lever of GEO.
If you use inconsistent terminology (e.g., “GEO” sometimes meaning “geotargeting” and sometimes “Generative Engine Optimization”), you increase ambiguity and raise the odds of incorrect summarization.
Freshness vs. evergreen: when recency matters
Recency matters most when:
- the query is news-like (“latest,” “today,” “2025,” “pricing,” “release”)
- the ecosystem shifts quickly (AI models, platform features, regulations)
Google itself emphasizes expansion and iteration cadence for AI Overviews (100+ countries in Oct 2024; 200+ countries and 40+ languages by May 2025). (blog.google)
Actionable recommendation (this section):
Design pages for passage retrieval: each H2 should answer one question cleanly, with a short summary, a list/table, and a “why it matters” line. Make it easy for a model to lift the right chunk without misframing it.
The GEO Content Playbook: Create Pages LLMs Can Cite (and Users Trust)

This is the part most teams want: the playbook. The hard truth is that GEO content looks a lot like “great reference content”—but with stricter packaging.
Featured snippet-first structure: definitions, lists, and step-by-step blocks
We lead with:
- a 40–60 word definition
- 5–7 key takeaways
- a table of contents
- and modular sections that can stand alone
This mirrors how AI answers are composed: short, structured, and extractable.
Evidence-driven writing: original data, citations, and transparent assumptions
Our internal rule: every meaningful claim needs a source or a method.
If we calculate something, we show the assumptions. If we reference platform behavior, we cite official docs or credible reporting.
This matters because the AI ecosystem is increasingly about attribution economics.
For example, Perplexity launched publisher compensation initiatives after plagiarism accusations, including revenue-sharing structures and publisher programs. (theverge.com)
And reporting indicates Perplexity later expanded/shifted its publisher compensation model with a $42.5M pool and subscription revenue sharing in at least one iteration. (wsj.com)
Whether you love or hate these models, the strategic direction is clear: citations are becoming monetizable surfaces, not just “nice-to-have links.”
Entity coverage: building topic maps and answering adjacent questions
We build “topic maps” that include:
- core definition
- “how it works”
- measurement
- tooling
- mistakes
- implementation steps
- FAQs
Then we ensure internal links connect these modules.
Updating strategy: revision logs, freshness signals, and versioning
We include:
- “Updated on” date
- change log (what changed and why)
- reviewer line for sensitive topics
This is partly for users—but also to reduce the chance that a model lifts outdated text.
Voice and style: neutral, precise, and quotable
Overly promotional language performed worse in our tests. We found that neutral, precise phrasing increased the chance of being cited faithfully.
Actionable recommendation (this section):
Rewrite your top 10 informational pages into “citation-ready modules”: definition block, takeaways, evidence table, FAQ, and revision log. Then re-test the same 50–100 prompts for citation lift.
Technical GEO: Make Your Content Easy to Retrieve, Parse, and Attribute

Content is necessary but not sufficient. We repeatedly saw technical issues block GEO gains.
Crawlability and indexation: logs, sitemaps, canonicals, and duplication control
If a page isn’t reliably indexed or is canonicalized incorrectly, it won’t be retrieved.
Our baseline checks:
- XML sitemaps clean and current
- canonicals correct
- thin duplicates consolidated
- internal links ensure no orphan pages
- log analysis confirms crawl frequency
Structured data: Schema.org for entities, authors, organizations, and FAQs
Schema helps clarify:
- Organization and Person entities
- Article metadata
- FAQPage where appropriate
- HowTo for step-by-step guides
But we treat schema as supporting infrastructure, not a ranking hack.
On-page semantics: headings, TOC, anchor links, and passage optimization
Passage optimization is technical + editorial:
- descriptive H2/H3 headings
- anchor links (jump-to sections)
- TOC for navigability
- consistent terminology
Performance and UX: Core Web Vitals, mobile rendering, and accessibility
Generative systems and users both prefer sources that:
- load reliably
- render well on mobile
- are readable and accessible
Attribution signals: authorship, references, and source transparency
We’ve seen attribution strengthen when:
- author bios exist
- references are explicit
- editorial policy is visible
Actionable recommendation (this section):
Run a “GEO technical audit” on your top pages: indexation, canonicals, duplication clusters, schema coverage, and passage structure. Fix technical blockers before rewriting content—otherwise you’ll optimize pages that models can’t reliably retrieve.
Comparison Framework: GEO Tactics and Tools (What to Use, When, and Why)

We organize GEO into four pillars: Content, Technical, Authority, Measurement.
Framework overview: Content, Technical, Authority, and Measurement pillars
- Content: citable modules, evidence, entity coverage
- Technical: indexation, schema, passage structure, performance
- Authority: digital PR, expert authors, corroboration across the web
- Measurement: harness + dashboards + experiments
Tool categories: SERP/AI tracking, log analysis, content optimization, entity research
We evaluate tools by whether they support:
- multi-surface testing (not just Google)
- citation capture (URLs cited)
- reproducibility (exportable runs)
- workflow fit (editorial + technical collaboration)
Side-by-side comparison criteria: coverage, accuracy scoring, workflow fit, cost
Our rubric (1–5):
- Coverage: can it track multiple AI surfaces?
- Accuracy scoring: can we store and rate outputs?
- Workflow: does it integrate with content ops?
- Cost: does it scale economically?
- Reproducibility: can we repeat tests weekly?
Recommendations by team size: solo, SMB, enterprise
- Solo: manual query set + spreadsheet scoring + GSC/GA4
- SMB: add SERP/AI monitoring + lightweight harness automation
- Enterprise: dedicated testing pipeline + log analysis + editorial governance + PR/authority program
Actionable recommendation (this section):
Choose tools based on measurement fidelity, not hype. If a tool can’t export citations, store outputs, and repeat the same query set over time, it’s not a GEO tool—it’s a demo.
Common Mistakes and Lessons Learned (What We’d Do Differently)

We’re candid here because GEO punishes shallow execution.
Mistake 1: optimizing for prompts instead of users (and losing trust)
Prompt-stuffing made pages less credible and sometimes reduced citations. It also increased summary distortion.
Mistake 2: thin “AI bait” pages without unique evidence
If your page has no unique data and no primary sourcing, it becomes interchangeable. Interchangeable pages don’t win selection.
Mistake 3: unclear entities and inconsistent terminology
This is a silent killer. Inconsistent definitions lead to incorrect summaries.
Mistake 4: ignoring attribution and editorial transparency
Teams underestimate how much author identity and editorial transparency matter in an era of synthetic content.
Mistake 5: measuring the wrong KPIs
Traffic alone is no longer the only KPI. You need:
- inclusion rate
- citation rate
- brand mention share
- accuracy score
- conversion quality
What we’d do differently (if we restarted):
- Start with measurement harness first, not content rewrites
- Build “definition + evidence” templates and enforce them editorially
- Invest earlier in entity consistency across the entire site
:::comparison :::
✓ Do's
- Build a repeatable harness (weekly/biweekly runs) and track AIR, CR, BMS, SAS—not just traffic.
- Package pages into citable modules (40–60 word definition, takeaways, lists/tables, references) so systems can lift passages cleanly.
- Strengthen editorial transparency (author/reviewer + revision log + explicit references) to reduce misattribution and drift.
- Expand entity coverage with topic maps and adjacent questions to win long-tail inclusion.
- Fix retrievability blockers first (indexation, canonicals, duplication clusters) before investing in rewrites.
✕ Don'ts
- Don’t prompt-stuff “conversational” filler that adds no evidence—tests showed it underperforms and can distort summaries.
- Don’t publish thin “AI bait” pages with no unique sourcing; interchangeable content rarely gets selected.
- Don’t rely on schema alone; it’s a multiplier, not a substitute for structure/evidence.
- Don’t let entity naming drift (e.g., “GEO” meaning two things); ambiguity increases incorrect summarization.
- Don’t report GEO success using rankings/clicks only; zero-click behavior and citation dynamics break that proxy.
Actionable recommendation (this section):
Create a GEO “red flags” checklist for editors: no evidence, unclear definitions, inconsistent entity naming, missing author/reviewer, no update log. Don’t publish until it passes.
Measurement and Reporting: Proving GEO ROI and Building a Feedback Loop

Leadership doesn’t fund what it can’t see. GEO needs a reporting model that connects to revenue.
Core GEO KPIs: inclusion rate, citation rate, and brand mention share
We use:
- AIR (Inclusion Rate) by topic cluster
- CR (Citation Rate) by surface (AIO vs chat vs answer engine)
- BMS (Brand Mention Share) vs competitors
- SAS (Summary Accuracy Score) trendline
Tracking setups: GSC, analytics, server logs, and AI surface monitoring
Practical tracking:
- group referrals from AI surfaces (where identifiable)
- capture citation URLs from monitoring tools/harness
- map AI referral landings to conversions
Experiment design: baselines, controls, and iteration cadence
We recommend 2–4 week GEO sprints:
- 2baseline run (query set)
- 4implement one change type (structure, evidence, entity coverage)
- 6re-run harness
- 8score inclusion/citation/accuracy
- 10ship learnings into templates
Reporting templates: executive dashboard vs. editorial action plan
We build two layers:
- Executive dashboard: GEO funnel + trendlines + outcomes
- Editorial plan: which pages to fix, what passages drifted, what evidence is missing
A useful mental model is a GEO funnel:
Indexed → Retrieved → Included → Cited → Clicked → Converted
This aligns with the broader reality that “zero-click” is already high in classic search (58.5% US in 2024). (sparktoro.com)
Actionable recommendation (this section):
Ship a GEO dashboard that reports: (1) inclusion rate, (2) citation rate, (3) accuracy score, (4) assisted conversions. If you can’t tie GEO to outcomes, it will get deprioritized.
FAQs

What is Generative Engine Optimization (GEO) in SEO?
GEO is optimizing your content and entity signals so generative systems can retrieve, trust, cite, and accurately summarize your pages—not just rank them. (linkedin.com)
How do I get my content cited in AI Overviews or ChatGPT-style answers?
We’ve had the best results with definition-first structure, evidence tables, clear entity naming, and strong editorial transparency (author/reviewer + references + update logs). Google has also iterated AI Overviews to show more prominent links, reinforcing that “supporting sites” are part of the design. (blog.google)
Does structured data (Schema) help with LLM visibility and citations?
Schema helps clarify entities and page type, but it’s not sufficient alone. In our tests, schema improved outcomes only when paired with strong content structure and evidence.
How is GEO different from traditional SEO and featured snippet optimization?
Featured snippets are a subset of “extractable answers.” GEO expands the goal: selection across multiple generative systems, citation stability, and summary accuracy—especially in environments where only a small portion of LLM citations overlap with top-10 Google rankings. (linkedin.com)
What metrics should I track to measure GEO performance and ROI?
Track inclusion rate, citation rate, brand mention share, accuracy score, and attributed/assisted conversions. Use a repeatable query harness and re-test weekly or biweekly.
Strategic Bottom Line (Executive Take)
GEO is not a hack layer on top of SEO. It’s a parallel optimization discipline built around how generative systems retrieve and synthesize information—and how attribution economics are evolving.
The “12% overlap” insight should change how you allocate resources: rankings are no longer a reliable proxy for being cited. (linkedin.com)
And the “zero-click” reality should change how you define success: visibility and trust can be valuable even when clicks decline. (sparktoro.com)
If we had to reduce this entire guide to one operating principle, it’s this:
Build pages that are retrieval-friendly, evidence-rich, entity-clear, and editorially trustworthy—then measure inclusion, citation, and accuracy like you measure rankings.
Key Takeaways
- GEO changes the win condition from “rank” to “selection”: LLM citation sets can diverge sharply from top-10 rankings (only ~12% overlap in the cited analysis). (linkedin.com)
- Zero-click makes citations and inclusion strategically valuable: with 58.5% of US searches ending in zero clicks (2024), visibility can happen without a visit. (sparktoro.com)
- Structure wins retrieval: definition-first blocks (40–60 words) plus takeaways and modular sections increased lift because passages are easier to extract and cite.
- Evidence improves both selection and accuracy: adding primary sources, explicit numbers, and methodology notes improved summary accuracy and reduced drift.
- Editorial transparency is an optimization lever: named authors, reviewers, and revision logs reduced misattribution and improved citation stability.
- Schema is a multiplier—not a rescue plan: structured data helped most when paired with strong content clarity, entity consistency, and evidence.
- Measurement is the foundation: a repeatable harness (query set + multi-surface runs + AIR/CR/BMS/SAS) is what turns GEO from anecdotes into an operating system.
Last reviewed: December 2025

Founder of Geol.ai
Senior builder at the intersection of AI, search, and blockchain. I design and ship agentic systems that automate complex business workflows. On the search side, I’m at the forefront of GEO/AEO (AI SEO), where retrieval, structured data, and entity authority map directly to AI answers and revenue. I’ve authored a whitepaper on this space and road-test ideas currently in production. On the infrastructure side, I integrate LLM pipelines (RAG, vector search, tool calling), data connectors (CRM/ERP/Ads), and observability so teams can trust automation at scale. In crypto, I implement alternative payment rails (on-chain + off-ramp orchestration, stable-value flows, compliance gating) to reduce fees and settlement times versus traditional processors and legacy financial institutions. A true Bitcoin treasury advocate. 18+ years of web dev, SEO, and PPC give me the full stack—from growth strategy to code. I’m hands-on (Vibe coding on Replit/Codex/Cursor) and pragmatic: ship fast, measure impact, iterate. Focus areas: AI workflow automation • GEO/AEO strategy • AI content/retrieval architecture • Data pipelines • On-chain payments • Product-led growth for AI systems Let’s talk if you want: to automate a revenue workflow, make your site/brand “answer-ready” for AI, or stand up crypto payments without breaking compliance or UX.
Related Articles
Yahoo's 'Scout' Chatbot: A New Contender in the AI Search Arena
Yahoo’s Scout chatbot signals a new phase in AI Retrieval & Content Discovery. Here’s what it means for Generative Engine Optimization and publishers.
Perplexity AI Image Upload: What Multimodal Search Changes for GEO, Citations, and Brand Visibility
How Perplexity’s image upload shifts multimodal retrieval, citations, and brand visibility—and what to change in GEO for Knowledge Graph alignment.