OpenAI GPT-5.3-Codex-Spark Deployment: Structured Data-First Rollout for Reliable AI Content Operations
Deep dive on deploying GPT-5.3-Codex-Spark with Structured Data: architecture, evaluation, costs, and governance to improve accuracy and AI visibility.
OpenAI GPT-5.3-Codex-Spark Deployment: Structured Data-First Rollout for Reliable AI Content Operations
A “Structured Data-first” deployment of GPT-5.3-Codex-Spark means you treat JSON-LD and entity facts as the primary production artifact—then use the model to generate, repair, validate, and ship that markup through governed pipelines. Instead of asking an LLM to write “better copy,” you constrain it to fill approved Schema.org templates using retrieved Knowledge Graph attributes, run deterministic validation, and continuously monitor for drift. The result is more reliable rich-result eligibility, lower schema error rates, and a cleaner machine-readable layer that AI answer engines can cite with higher confidence.
This article focuses on deployment mechanics for Structured Data pipelines—generation, validation, publishing, monitoring, and governance—using GPT-5.3-Codex-Spark as the execution layer. It does not attempt a broad model capability review.
Executive Summary: Why a Structured Data-First Deployment Matters for GPT-5.3-Codex-Spark
Featured snippet: What is a Structured Data-first deployment?
Definition (copy/paste for playbooks)
A Structured Data-first deployment is an AI rollout where: (1) Schema.org/JSON-LD coverage is treated as a core product requirement, (2) entities and typed relationships are modeled in a Knowledge Graph, (3) retrieval + generation is grounded on machine-readable facts (not inference), and (4) outputs are continuously validated and monitored with error budgets and rollback controls.
Where GPT-5.3-Codex-Spark fits in an AI Content Strategy stack
In a modern AI content operations stack, GPT-5.3-Codex-Spark is most valuable as the execution layer for structured outputs: it can transform source data into JSON-LD, repair broken markup, map CMS fields to Schema.org properties, and generate schema diffs suitable for code review. This is especially relevant as OpenAI expands enterprise integration patterns (agent/workflow management) via its Frontier platform coverage in industry reporting. (External source: TechCrunch)
Deployment teams should also anticipate that AI search behavior and evaluation paradigms are changing quickly; align your rollout with how answer engines judge relevance and trust. For deeper context on evaluation, see Re-Rankers as Relevance Judges: A New Paradigm in AI Search Evaluation.
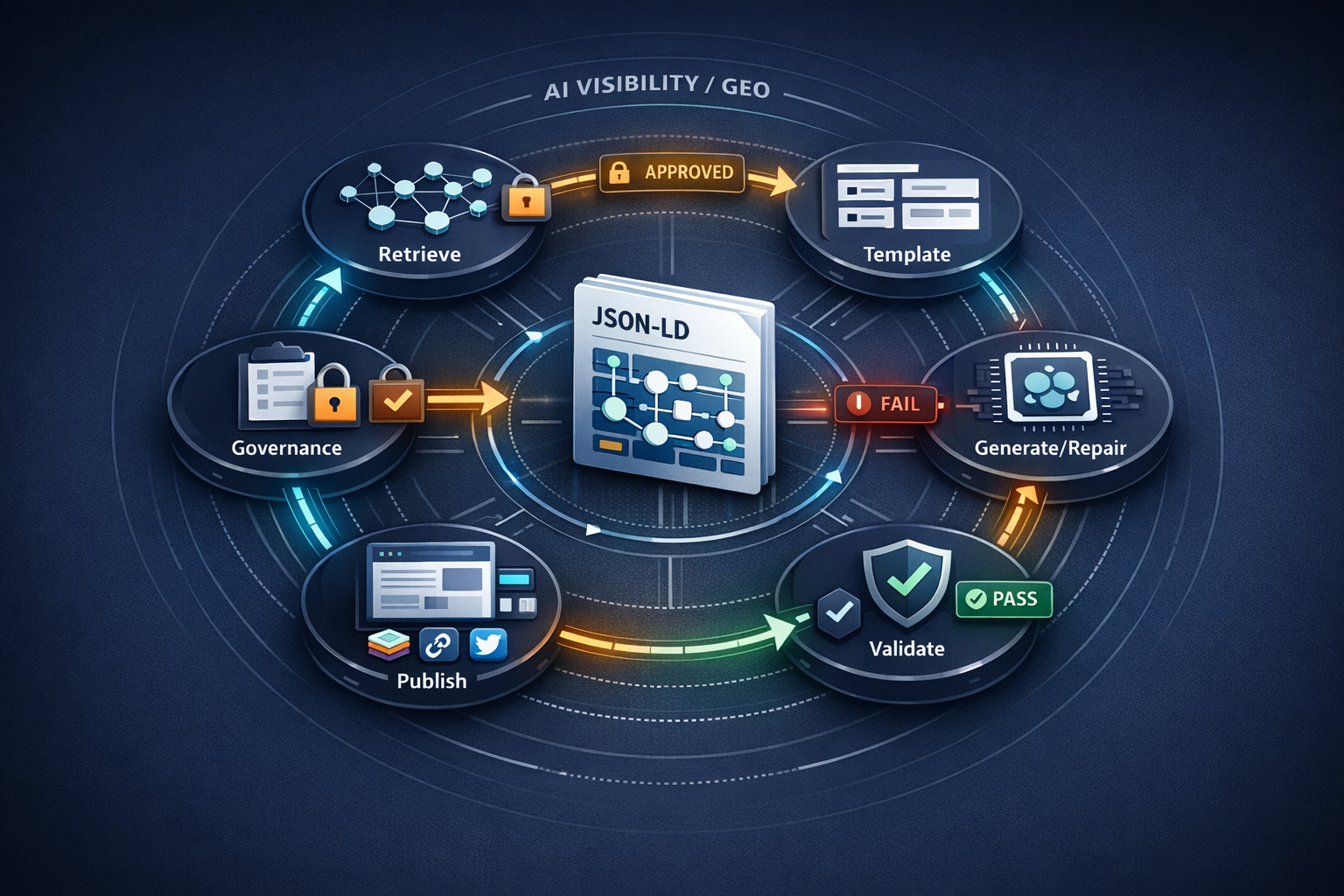
Reference Architecture: Deploying GPT-5.3-Codex-Spark into a Structured Data Pipeline
System components: CMS, schema registry, Knowledge Graph, validators, and deployment hooks
A reliable architecture uses the model where it’s strong (structured transformation) and uses deterministic systems where they’re required (policy, correctness, provenance). A common pattern:
- CMS/content store → extract entities and page metadata (IDs, authors, dates, product SKUs, etc.).
- Knowledge Graph → store canonical entities + typed relationships (e.g., Person→worksFor→Organization; Product→offers→Offer).
- Schema registry → approved JSON-LD templates per content type (Article, Product, FAQPage, HowTo, Organization) and per entity class.
- GPT-5.3-Codex-Spark → fill template slots, repair markup, generate diffs, and annotate provenance (which KG fields populated which schema fields).
- Validation layer → JSON schema checks + Schema.org conformance + business rules + regression tests.
- Publish hooks → deploy markup (headless, server-side render, or CMS fields) with versioned templates + rollback.
- Monitor → track validation errors, rich result eligibility, and anomaly detection in Search Console.
Grounding strategy: Knowledge Graph + retrieval to constrain Structured Data generation
Grounding is the difference between “LLM-generated markup” and “production schema.” Retrieval should pull canonical attributes (entity IDs, names, dates, offers, authorship) from your Knowledge Graph, and the model should be required to map each emitted property to a source field. This makes validation and rollback deterministic and helps answer engines trust your entity layer. If you’re bridging internal knowledge with web sources, the pattern aligns with broader AI search approaches discussed in Perplexity AI’s Internal Knowledge Search.
Security & access: secrets, least privilege, and audit trails for schema changes
- Use least-privilege service accounts: the model runner can read approved templates + KG fields but cannot write to the KG or publish directly.
- Store secrets in a vault; rotate API keys; log every generation request (page ID, template version, KG snapshot hash).
- Require audit logs for schema changes (who/what/why) and tie deployments to CI checks and approvals.
If GPT-5.3-Codex-Spark can invent properties, URLs, IDs, reviews, or offers, you’re effectively shipping unverified claims in a machine-readable format. Treat schema generation like code: template registry, strict allowlists, deterministic validators, and rollbacks.
Implementation Deep Dive: Generating and Validating JSON-LD with GPT-5.3-Codex-Spark
Prompting & constraints: template-filling, enums, and property whitelists
Pass a template, not a blank page
Provide a versioned JSON-LD template with placeholders (e.g., {{headline}}, {{author.@id}}). Instruct the model to fill only placeholders and to preserve unknown fields as null.
Enforce JSON-only + property allowlist
Require a JSON-only response. Reject any keys not present in the allowlist for that template. Use enums for @type and other high-risk fields (e.g., availability, priceCurrency).
Require provenance mapping
Add a parallel structure (not published) that maps each populated property to its source (KG field, CMS field, or explicitly “unknown”). Fail validation if required fields are “inferred.”
Disallow hallucinated URLs and IDs
Only allow URLs/IDs from retrieval results or deterministic builders (e.g., canonical URL builder). If a URL isn’t retrieved/constructed, it must be null.
Validation stack: Schema.org rules + business logic + regression tests
Use layered validation so failures are explainable and fixable:
| Layer | What it catches | Example rule |
|---|---|---|
| JSON schema | Syntax, types, required keys | price must be number; datePublished must be ISO-8601 |
| Schema.org conformance | Missing recommended/required properties; invalid types | Article must include headline and author; Organization should include name and url |
| Business rules | Policy/brand correctness; claim boundaries | author.@id must exist in KG; priceCurrency must be USD/EUR/etc.; no Review unless verified source exists |
| Regression tests | Unexpected drift and breakage | Field-level diff must not remove required properties; template version bump required for structural changes |
For monitoring and faster anomaly detection, pair these checks with Search Console workflows; see Google Search Console 2025 Enhancements: Hourly Data + 24-Hour Comparisons for Faster GEO/SEO Anomaly Detection, and for unified signal diagnosis across channels, see Google Search Console Social Channel Performance Tracking.
Deployment workflow: CI/CD for Structured Data (preview, diff, approve, ship)
Two rollout modes (choose by risk level)
| Mode | Best for | Controls | Tradeoffs |
|---|---|---|---|
| Autopublish (low-risk templates) | Organization, BreadcrumbList, basic Article | Strict allowlist + validators + canary + auto-rollback | Fast, but requires mature monitoring |
| Human-in-the-loop (high-risk templates) | Product/Offer, Review, Medical/Finance claims | Diff review + approvals + provenance enforcement | Slower, but minimizes false-claim risk |
Example: Validation pass rate by content type (baseline vs. after template registry + grounding)
Illustrative KPI you should track: percent of pages passing all validation layers on first run. Replace with your measured data segmented by template version.
Performance & ROI Measurement: What to Track After Deployment
SERP/AI visibility metrics tied to Structured Data
- Rich result eligibility and enhancement reports (errors/warnings) by template version.
- Impressions/clicks/CTR for pages with valid JSON-LD vs. invalid/missing (matched by topic and traffic tier).
- AI answer inclusion/citation rate where measurable (e.g., tracked prompts + citation auditing).
Because algorithmic expectations can shift toward quality signals, monitor how content performance changes after major updates. An example of this quality emphasis is discussed in Search Engine Land’s reporting on Google Discover updates. (External source: Search Engine Land)
Quality metrics: entity consistency, Knowledge Graph alignment, and error budgets
Operationally, Structured Data quality is an error-budget problem. Track:
- Entity resolution accuracy: sameAs correctness, mismatched IDs, and author/organization disambiguation.
- Duplicate entity rate: number of distinct IDs representing the same real-world entity.
- Structured Data error budget: allowed critical errors per 10k pages, with automated rollback if exceeded.
If you’re also evaluating fairness and bias in AI-driven visibility (including KG checks), align your governance metrics with LLMs and Fairness: How to Evaluate Bias in AI-Driven Search Rankings (with Knowledge Graph Checks).
Cost metrics: tokens, latency, and engineering overhead
Cost modeling should be per page and per template version: tokens for generation/repair, retrieval cost, validation compute, and human review time. Industry reporting suggests GPT-5.3-Codex-Spark is positioned for fast interactive coding workloads (including very high throughput under optimal conditions), which can reduce pipeline latency for schema repairs and diffs. (External source: Tom’s Hardware)
Pre/post rollout trend to monitor: Structured Data critical errors per 1,000 pages
Track critical validation errors over time with annotations for template releases and policy changes. Values below are illustrative placeholders.
Governance, Risk, and Expert Perspectives: Keeping Structured Data Trustworthy at Scale
Risk model: hallucinated entities, policy violations, and schema spam
Structured Data is a claim layer. If the model invents authorship, reviews, availability, pricing, or medical/financial attributes, you can trigger rich result loss, manual actions, or long-term trust erosion. Mitigate by making provenance mandatory and by disallowing high-risk properties unless they are backed by a source-of-truth field in the Knowledge Graph.
Treat JSON-LD like production code: every field needs an owner, a source, a test, and a rollback plan.
Governance controls: approvals, provenance, and auditability
- RACI for schema templates: SEO owns requirements, KG team owns entity mappings, engineering owns CI/CD, legal/compliance owns claim policies.
- Provenance enforcement: every emitted field must map to a KG/CMS source; otherwise null.
- Auditability: log template version, KG snapshot hash, generator version, reviewer approvals, and publish timestamp.
For broader AI search visibility signals and E-E-A-T/citation confidence considerations, connect this governance layer to Google Algorithm Update March 2025: What the Core Update Signals for AI Search Visibility, E-E-A-T, and Citation Confidence.
Expert quote opportunities: SEO, schema, and knowledge graph stakeholders
If you’re building internal enablement, collect short, attributable guidance from three roles and embed it into your schema playbooks:
- Technical SEO lead: what “good” looks like (eligibility, stability, and error budgets).
- Knowledge Graph engineer: entity identity rules, sameAs policy, and relationship constraints.
- Legal/compliance: claims you must not encode (or must disclose) in machine-readable markup.
Your goal is not “more schema.” Your goal is auditable, KG-grounded schema that stays valid through releases, updates, and model changes—so both search engines and AI answer systems can rely on it.
Key Takeaways
Structured Data-first deployment = templates + Knowledge Graph grounding + deterministic validation + continuous monitoring (treat schema like code).
Use GPT-5.3-Codex-Spark for slot-filling, repair, and diffs—not free-form JSON-LD generation—backed by a schema registry to prevent drift.
Provenance is the anti-hallucination control: every emitted field must map to a source-of-truth attribute or be null.
Prove ROI with pre/post metrics: validation pass rate, critical errors per 1k pages, rich result impressions/CTR, and operational MTTF—segmented by template version.
FAQ
Next steps: if you’re aligning this deployment with broader AI-search competition and model releases, connect your measurement framework to OpenAI's GPT-5.2 Release: A New Contender in the AI Search Arena, and ensure your technical foundations (performance + structured, KG-ready content) are solid per Google Core Web Vitals Ranking Factors 2025: What’s Changed and What It Means for Knowledge Graph-Ready Content.

Founder of Geol.ai
Senior builder at the intersection of AI, search, and blockchain. I design and ship agentic systems that automate complex business workflows. On the search side, I’m at the forefront of GEO/AEO (AI SEO), where retrieval, structured data, and entity authority map directly to AI answers and revenue. I’ve authored a whitepaper on this space and road-test ideas currently in production. On the infrastructure side, I integrate LLM pipelines (RAG, vector search, tool calling), data connectors (CRM/ERP/Ads), and observability so teams can trust automation at scale. In crypto, I implement alternative payment rails (on-chain + off-ramp orchestration, stable-value flows, compliance gating) to reduce fees and settlement times versus traditional processors and legacy financial institutions. A true Bitcoin treasury advocate. 18+ years of web dev, SEO, and PPC give me the full stack—from growth strategy to code. I’m hands-on (Vibe coding on Replit/Codex/Cursor) and pragmatic: ship fast, measure impact, iterate. Focus areas: AI workflow automation • GEO/AEO strategy • AI content/retrieval architecture • Data pipelines • On-chain payments • Product-led growth for AI systems Let’s talk if you want: to automate a revenue workflow, make your site/brand “answer-ready” for AI, or stand up crypto payments without breaking compliance or UX.
Related Articles

Perplexity's Publisher Program Expansion: A New Era for Content Monetization
Deep dive on Perplexity’s expanded Publisher Program—how monetization works, what Structured Data signals matter, and KPIs publishers should track.
The Ultimate Guide to AI Content Strategy: Mastering Content for Both Human Readers and AI Systems
Learn a complete AI content strategy: research, workflows, governance, and measurement to create content that ranks, converts, and works for AI search.