Perplexity’s “Computer” and the Next Phase of Generative Engine Optimization: Coordinating AI Agents for Better Citations
News analysis of Perplexity’s “Computer” and what AI agent coordination means for Generative Engine Optimization, AI citations, and brand visibility.
Perplexity’s “Computer” and the Next Phase of Generative Engine Optimization: Coordinating AI Agents for Better Citations
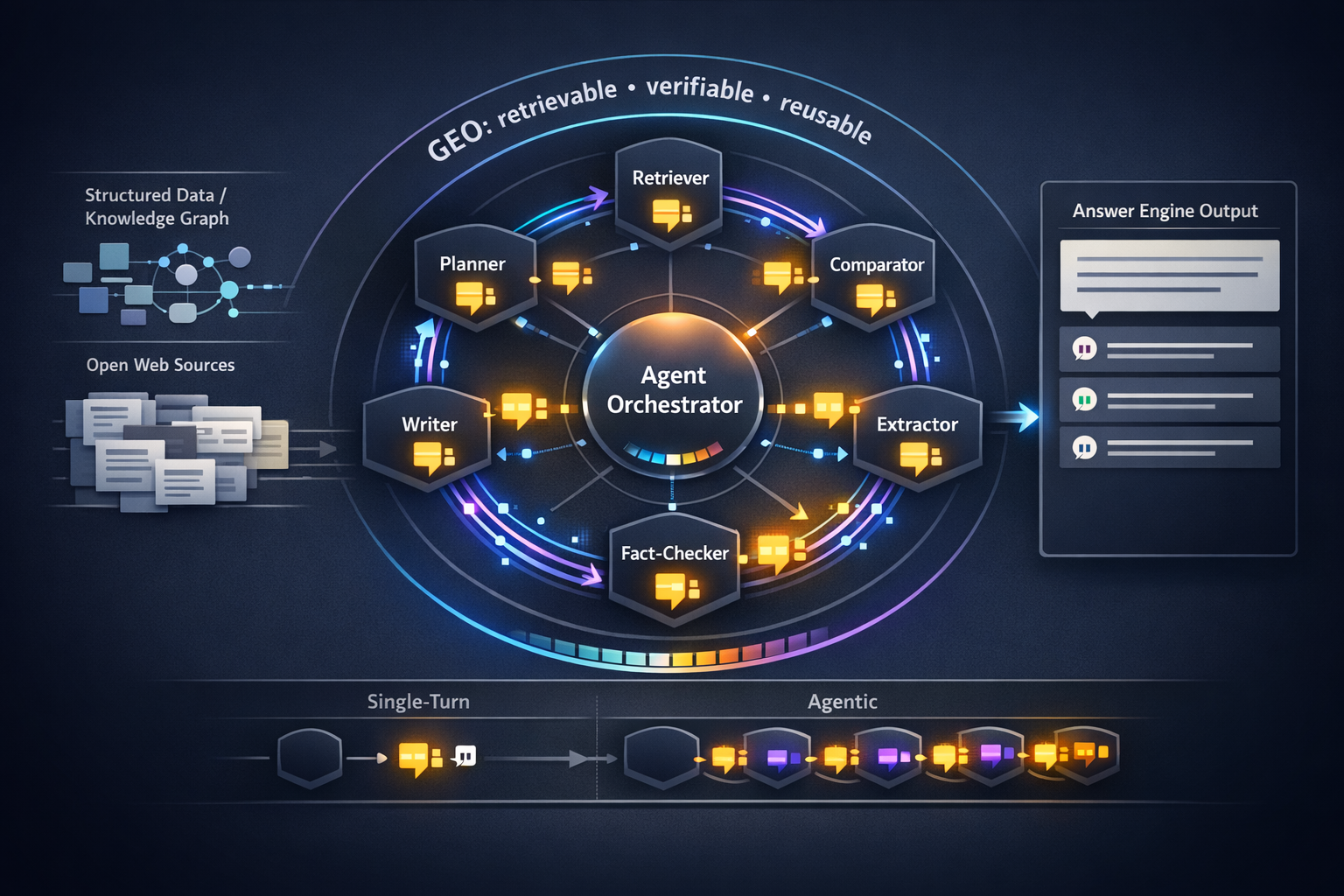
Perplexity’s “Computer” signals a shift from single-answer chatbots to coordinated, tool-using workflows where multiple agents (or sub-tasks) collaborate to complete a goal. For Generative Engine Optimization (GEO), this changes the citation game: instead of “win the final answer,” brands must be consistently retrievable, verifiable, and reusable across multiple steps—planning, comparing, extracting, checking, and then writing. The upside is more retrieval events per session (more chances to be cited). The downside is stricter provenance demands and higher citation volatility as agents cross-check sources and discard weak ones.
In agentic workflows, citations become step-dependent: your content might be used for early retrieval but dropped during verification. GEO programs need to optimize for both selection and retention across the whole task.
What Perplexity’s “Computer” signals: from chatbot answers to coordinated action
The news hook: why “Computer” matters now
“Computer” is best understood as a product direction: users don’t just want an answer—they want an outcome. That outcome often requires multiple actions: gather sources, check recency, compare options, extract constraints, generate a plan or draft, and sometimes iterate. In systems like this, the “answer engine” behaves more like an orchestrator of specialized components (retrieval, browsing, summarization, verification), which expands where and when sources can be pulled in.
This aligns with a broader trend toward structured, machine-readable content pipelines. For monitoring implications of new structured capabilities in frontier models, see OpenAI GPT-5.4 Launch (2026): What the New Structured Data Capabilities Mean for AI Visibility Monitoring.
How agent coordination changes the citation surface area
In a classic single-turn Q&A, there’s typically one retrieval moment (or a small handful) and one synthesized answer. In coordinated agent workflows, retrieval can happen at every step: decomposing the task, collecting candidates, validating claims, checking edge cases, and final assembly. Each retrieval moment is a “citation lottery,” but each is also a filter: only sources that remain consistent, attributable, and extractable survive to the end.
This is why content structure is no longer just “nice for readers”—it’s a machine-readability advantage. For evidence on how structure influences LLM citation behavior, explore The Impact of Content Structure on LLM Citations: Insights from Recent Studies.
Benchmark model: retrieval events and citations in single-turn vs agentic tasks
Illustrative benchmark (not vendor-reported): agentic workflows tend to trigger more retrieval calls and intermediate citations per completion than single-turn Q&A, increasing opportunity but also verification pressure.
Treat the chart as a planning heuristic: if your team only optimizes for the “final answer,” you’re leaving upstream steps—where sources are shortlisted and validated—completely unaddressed.
Inside the coordination loop: where citations are won or lost
Task decomposition → retrieval → synthesis → verification
Most agentic systems follow a recognizable loop, even if the UI hides it:
- Decompose the task into sub-questions (constraints, definitions, comparisons).
- Retrieve candidate sources for each sub-question (SERP-like retrieval, browsing, or index lookups).
- Synthesize a draft plan/answer from candidates (often with intermediate notes).
- Verify (cross-check facts, reconcile conflicts, enforce recency, validate entities).
Citations can attach at multiple nodes: a source might be cited during comparison, then replaced by a primary source during verification. This is also where knowledge graph grounding becomes decisive—agents need stable entity IDs and unambiguous references to avoid “near-match” confusion. For a practical GEO framing of entity optimization and knowledge-graph-led visibility, see The Rise of Generative Engine Optimization (GEO): Navigating AI-Driven Search Landscapes (Case Study: Knowledge Graph–Led Entity Optimization).
Citation Confidence in agentic workflows
In a coordinated workflow, “Citation Confidence” is not a single score—it’s a moving threshold across steps. A page that looks useful at retrieval time can fail at verification time if it lacks authorship, dates, clear entities, or extractable formatting. Common failure modes that suppress citations include:
- Conflicting claims without references (agents prefer corroboration).
- Missing timestamps or unclear update history (recency filters may drop it).
- Ambiguous entity naming (brand/product names that collide with others).
- Paywalls, blocked resources, heavy client-side rendering, or non-extractable layouts.
If your page is hard to parse or hard to attribute, it may be used to understand the topic but replaced by a cleaner, better-provenanced source at the final step—meaning you get zero visible citation even though it influenced the output.
| Citation Confidence factor | What agents look for | How to improve | Stage most affected |
|---|---|---|---|
| Entity clarity | Unambiguous product/company names; consistent “about” signals | Define entities early; align naming across pages; add Organization/Product schema | Decomposition + retrieval |
| Provenance | Author, datePublished/dateModified, methodology, primary references | Add visible bylines, update logs, citations list; use Article schema | Verification + final synthesis |
| Extractability | Clean HTML, descriptive headings, stable tables, minimal gating | Use semantic headings; put key claims in text (not images); avoid blocked rendering | Retrieval + synthesis |
This “scoring” approach also helps you operationalize repairs: it turns citation outcomes into fixable page attributes. For a deeper diagnostic/repair framing, see Generative Engine Optimization (GEO) — citation diagnostics & repair.
Implications for Generative Engine Optimization: designing content for agent-to-agent handoffs
Structured data and knowledge graph alignment for agent readability
Agent coordination rewards “handoff-ready” content: pages that can be picked up by one agent, validated by another, and quoted by a third without losing meaning. The most reliable way to enable this is to reduce ambiguity with structured data and knowledge graph alignment—consistent entity naming, stable identifiers, and explicit relationships (product → company, feature → plan, policy → jurisdiction).
This is also why knowledge graph operations are becoming a core GEO capability, not a niche data project. For an applied orchestration example, see Case Study: Using Marketing Automation Platform Features to Orchestrate Knowledge Graph Updates for AI Visibility Monitoring.
Source packaging: passages, provenance, and update signals
To win citations in multi-step workflows, optimize for three packaging properties:
- Passage-level quotability: short sections with a clear claim, scope, and definitions (so an agent can lift it without rewriting).
- Provenance completeness: author, credentials, dateModified, methodology, and links to primary sources.
- Update signals: visible “last updated” plus a changelog for important pages (pricing, specs, policies).
Expected GEO lift from handoff-ready improvements (directional)
Directional model: structured data + clearer passage packaging tends to increase selection and retention across agentic steps, improving final-answer citation likelihood.
A caution: structured data helps reduce ambiguity, but it can’t compensate for missing substance. Agents still need extractable, corroborated claims—especially in sensitive categories where safety and reliability policies tighten. For context on how safety standards can influence verification behavior, see Anthropic’s policy overview: https://en.wikipedia.org/wiki/Anthropic%27s_Responsible_Scaling_Policy.
What this means for the AI Citations cluster: measurement, monitoring, and attribution
New metrics: agentic citation rate and step-level attribution
Agent coordination requires new GEO metrics that match the workflow. Consider adding these to your AI Visibility reporting:
- Citations per task (median and distribution): how many sources are used/shown for a standardized task.
- Unique domains per task: indicates how broad the agent’s candidate set is (and how competitive the slot is).
- Step-level citation retention: which domains appear early vs survive to the final response.
- Time-to-citation: which step first introduces your domain (early introduction often correlates with final retention).
Monitoring workflows: prompts, tasks, and reproducible tests
Build a task suite (25–50 tasks)
Use goal-oriented prompts that force multi-step behavior (e.g., “compare vendors,” “draft a policy,” “plan a rollout,” “create a compliance checklist”). Keep tasks stable month to month.
Lock test conditions
Run in the same geography, language, and account state when possible. Record date/time and any tool settings (browsing on/off).
Log citations and classify them
Capture cited URLs, domains, and (if visible) where they appeared in the workflow. Tag by entity/topic so you can see which clusters are gaining or losing AI Visibility.
Diagnose drops as “selection” vs “retention” problems
If you’re never cited, it’s a selection issue (entity ambiguity, weak topical relevance, accessibility). If you appear early but disappear later, it’s a retention issue (provenance, conflicts, extractability).
Example benchmark view: share-of-citations by task cluster (template)
Use a radar/heatmap-style view to compare how often your domain is cited across different task clusters. Populate with your monthly task-suite runs.
As you scale monitoring, incorporate fairness and bias checks—agentic systems can over-amplify certain narratives depending on what’s most retrievable and “verifiable.” For a GEO-focused comparison review on bias in rankings, see LLMs and Fairness: Addressing Bias in AI-Driven Rankings (Comparison Review for AI Visibility).
Outlook: coordination will intensify provenance demands (and reward credible publishers)
Predictions for 6–12 months: verification agents and stricter sourcing
As agent coordination becomes mainstream, expect verification to become more explicit: separate “check” steps, stronger preference for primary sources, and higher penalties for unclear provenance. That rewards publishers who treat their site like a reference system: clear authorship, stable URLs, transparent updates, and explicit citations to upstream evidence.
It also increases the value of transparency in knowledge graphs and sourcing. For the governance angle, see Industry Debates: The Ethics and Future of AI in Search—Why Knowledge Graph Transparency Must Be Non‑Negotiable.
Risks: citation volatility, scraping constraints, and brand misattribution
More steps mean more chances for your citation to be replaced. This creates volatility: week-to-week, the same task may cite different domains as agents test alternatives. Brands should plan for continuous GEO hygiene (refreshing key pages, maintaining schema, ensuring accessibility) rather than one-time “optimizations.”
There are also operational constraints: robots rules, paywalls, and rendering choices can make your content unreachable to retrieval agents. And when multiple sources are stitched together, misattribution risk rises—another reason to build first-party reference hubs with unambiguous entity signals.
Template: citation volatility vs freshness/accessibility signals
Use this model to correlate week-over-week citation variance with page freshness (dateModified recency) and accessibility (e.g., blocked rendering, paywalls). Populate with your tracked task suite.
In agentic search, the “best” source is often the one that remains consistent and attributable after cross-checking—not the one with the most persuasive copy.
For additional background on Perplexity as a product and its evolution, see: https://en.wikipedia.org/wiki/Perplexity_AI.
Key Takeaways
Perplexity’s “Computer” represents a shift to multi-step, coordinated workflows—expanding the number of retrieval moments and citation opportunities per task.
In agentic pipelines, citations are won twice: first at selection (retrieval) and again at retention (verification). Optimize for both.
Handoff-ready content (clear passages, strong provenance, and structured data) is more likely to survive cross-checking and earn final-answer citations.
Measure what agent systems actually do: citations per task, step-level retention, time-to-citation, and share-of-citations across standardized task suites.
FAQ: Perplexity “Computer,” agent coordination, and GEO citations

Founder of Geol.ai
Senior builder at the intersection of AI, search, and blockchain. I design and ship agentic systems that automate complex business workflows. On the search side, I’m at the forefront of GEO/AEO (AI SEO), where retrieval, structured data, and entity authority map directly to AI answers and revenue. I’ve authored a whitepaper on this space and road-test ideas currently in production. On the infrastructure side, I integrate LLM pipelines (RAG, vector search, tool calling), data connectors (CRM/ERP/Ads), and observability so teams can trust automation at scale. In crypto, I implement alternative payment rails (on-chain + off-ramp orchestration, stable-value flows, compliance gating) to reduce fees and settlement times versus traditional processors and legacy financial institutions. A true Bitcoin treasury advocate. 18+ years of web dev, SEO, and PPC give me the full stack—from growth strategy to code. I’m hands-on (Vibe coding on Replit/Codex/Cursor) and pragmatic: ship fast, measure impact, iterate. Focus areas: AI workflow automation • GEO/AEO strategy • AI content/retrieval architecture • Data pipelines • On-chain payments • Product-led growth for AI systems Let’s talk if you want: to automate a revenue workflow, make your site/brand “answer-ready” for AI, or stand up crypto payments without breaking compliance or UX.
Related Articles

ChatGPT Optimization in 2026: A Working Checklist for Getting Your Brand Cited, Not Just Ranked
How ChatGPT retrieves and cites sources in July 2026, with a sourced Generative Engine Optimization checklist covering crawler access, extractable answers, entity signals, and measurement.

The EU Wants Google to Open Up Search Data to Rival AI Engines
EU plans to open Google Search data to rival AI engines. Learn why Structured Data—not raw click logs—will determine who can retrieve and cite the web.